It’s common for enterprise website developers to implement search engines with out-of-the-box functionality, point it at their content repositories, and then just leave it at that. Search is becoming something of a neglected orphan, in part because packaged search products are relatively easy to implement, and then even more easily forgotten.
Unfortunately, the results are too often plagued by problems. You know something’s gone wrong when a perfectly clear query returns results that are not only irrelevant, but seemingly deranged. Pages with a logical relationship to the initial request compete for placement among what Jared Spool fittingly calls “wacko results.”1 The majority of participants walking into my usability tests report they don’t trust embedded site search to help them find what they’re looking for.
Quality search results only come about through applied effort, requiring in particular the skills of an information architect.2 And IAs must be ready to go well beyond their traditional front-end role, digging into the functional backend and source data of the search engine. This article outlines how we can bolster findability and win back users’ confidence.
Conceptualizing the Task
The results of any given search are impossible to predict with precision (short of having tried it before). That’s because five distinct variables combine to determine its outcome (Figure 1):
- Search engine. The algorithmic gears that parse the query and assign pages relevance.
- Content. The documents searched.
- Index. A catalog of the locations of every word in every document. This is what allows Google to miraculously find 5 billion instances of the word “the” in 0.2 seconds.
- User input. The keywords and other parameters the user submits.
- Results display. The way the data returned by the search engine is presented.
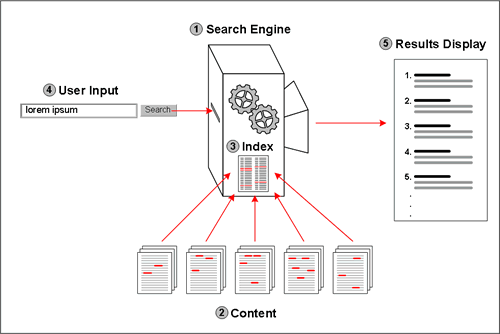
Figure 1. Five variables that determine the success of a site search.
Critically, the search engine isn’t the only factor that determines the outcome, so search can’t be seen purely as a technology problem. It’s important for organizations to realize that their investment in search doesn’t end with the product’s implementation; the most successful approaches will go further to include strategies addressing all of the outside variables.
Strategies
Several engine products allow you to tweak the search engine’s algorithm itself, but I don’t recommend it. That would be like doing brain surgery to fix a speech impediment—whether or not you solve that problem, you’ll inevitably cause a great many more. Changing the algorithm affects all searches, including the ones that already work just fine. So it’s easiest to keep it stable and modify the factors surrounding it.
Taking the search engine as a constant, then, there are four variables that affect the quality of search. Strategies for improving each of these are proposed below.
Strategy 1: Make the Content Machine-Readable
Search engines can provide better results when they’re given better content. The trick is to provide a basis for inferring the content’s meaning.
Structural Markup
The XHTML structure of pages is relevant to the IA, because content that is more machine-readable will be easier to find using search. Pages should extensively use the correct semantic elements: <h1> through <h6>, <p>aragraph, <q>uotation, <caption>, and so on, as well as semantically named “class” attributes. This will help the search engine compare the usage of terms among pages, to distinguish the central topic of a page from peripheral concepts (Figure 2). While IAs typically don’t mark up individual pages, they can influence the process by specifying template-level semantic elements in their wireframes and participating in periodic content reviews.

Figure 2. Structural markup explains that Jupiter is the central topic of page A, while in page B it’s just one of several subpoints on observing planets.
Standard Meta Tags
Most websites use keywords and descriptions in meta tags, but not often as part of a larger strategy. The first step is to create a controlled vocabulary, a standardized set of keywords.3 If you tag them as “teachers” over here, but “professors” over there, the search engine will have a hard time understanding why they’re the same thing. The keywords should also reflect actual terminology from the page itself (especially headings) and be reinforced in the description tag.
More Metadata
Go beyond keywords. Tags that describe the target audience groups, the sector of a financial service, or the cuisine of a recipe page provide more ways to compare and contrast the content; search engines will read as much meta information as you give them. There is a practical limit to how much you can do, which makes user-defined tags well worth considering.
Ontology
Humans know that pugs are dogs, and dogs chase cats, and cats play with yarn, but these relationships are lost on computers. An ontology is a list of concepts linked by the ways they relate to one another (Figure 3), helping the search engine grasp the content’s meaning. If your search product supports ontologies (several do), this can significantly improve the quality of the results.4
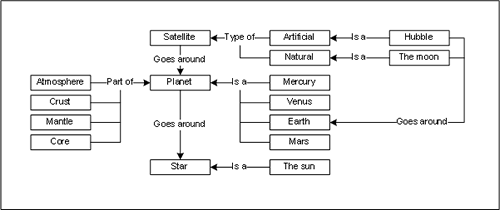
Figure 3. An ontology explains the relationships between concepts.
Strategy 2: Index All of the Right Data
Indexes have made searching remarkably expedient, but the way they’re built has a lot to do with the quality and reliability of results. Proper indexing requires taking a hands-on approach, and the IA has an interest in working with the development team to influence it.
Ignoring Unnecessary Content
Search engines will automatically index the entire content of a page, regarding everything as equally important. This is a problem because the navigation, for example, will contain terms that are specifically relevant to the siblings, parents, and children of a page, and not to the page itself (Figure 4). There are several methods of excluding this content; the important thing is to make sure that it’s done, because this is one of the most common reasons why searches return bizarre results.
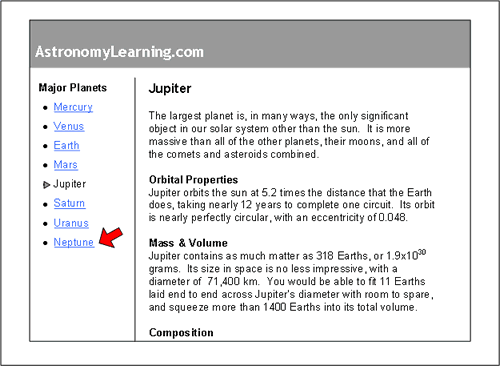
Figure 4. A search for “Neptune” may return results that include this page about Jupiter because the term “Neptune” appears here in the navigation.
Getting All Resources
Users reasonably expect a search to return all of the website’s relevant publicly available documents. Unfortunately, many search products can’t index .pdf, .doc, .xls, .ppt, and similar files, and you can forget about content locked away in audio or video files. The best fix is to convert application files to XHTML and provide transcripts or summaries of multimedia files. This can be a big job, so you may want to initially convert just the most commonly accessed documents.
Strategy 3: Make the Most of User Input
It can be difficult to figure out how to phrase a query. Users have to express what are often complicated concepts in that particular set of words that a given search engine will like. It’s important to make the most of what users submit on their first attempt, because they’re much less likely to make a second.5
Query Expansion
All contemporary search vendors offer some type of query expansion, where the search engine automatically looks for words related to the ones the user actually entered (Figure 5). Word stemming, which searches for different forms of the same word, is usually enabled by default. However, the thesaurus, which searches for equivalent and related terms, requires manual work.6

Figure 5. Searches shouldn’t only look for the terms as the user entered them, but for related and alternate forms of those terms.
You can go overboard defining synonyms, but the problem is usually too little (by which I mean “none at all”) rather than too much.8 Search logs are the best resource for discovering synonyms, related terms, and common misspellings. Set up ongoing reviews to add terms that users actually submit to the thesaurus, drawn from the wealth of data that’s freely available in the logs. The number of successful first attempts will rise dramatically over time.
Syntax Conventions
Users should be able to submit searches in whatever way they learned to write them. Unfortunately, search engines have different syntaxes for the standard operators (And, Or, Not, exact string). You can’t rely on a help file—it’s one of people’s least favorite things to read. The parser should instead be scripted to accept all common syntax conventions, so the user doesn’t have to guess. It should also use “And” as the default operator, which will appropriately limit the results downward as more terms are added to the search.
Assisting Query Formulation
Suggestion functions provide users with a list of similar queries that other people have tried as they type. This makes a lot of sense, since it can be difficult to put a complex idea into words or to recall the precise name of an item. Stellar examples of suggest functions include Google Suggest, AllTheWeb, and Apple’s website.
Strategy 4: Build the Results Page Around the User’s Needs
The results page should be designed to help users find matches for their interests as quickly as possible. This is closer to the IA’s typical interface design role, yet it’s still uncommon to see much more than the vendor’s out-of-the-box functionality on search results pages.
Showing Relevance
Sometimes a search engine will return the right results, but the user will fail to recognize it. Users need to see why results are relevant to their searches. There are two simple ways to do this.
The first is to show a text excerpt from the page that contains the terms from the user’s query, instead of the <meta>description field. The description may vary greatly from the user’s entered query—especially on long pages—and it may not be at all clear why a particular page was retrieved. Instead, an excerpt of the actual content that matches the search will directly explain why a user might want to click through to that page.
The second way to show relevance is to bold the terms in the excerpt that match terms in the user’s original query. That will help the user to quickly scan the page for the results that have the right words in the right context (Figure 6).

Figure 6. Excerpting and term highlighting allow the user to understand how each result relates to the query, and quickly identify the ones that are most relevant.
Best Bets
Despite all optimization efforts, search engines sometimes still miss strong associations that are obvious to people. In cases where particular keywords should be returning specific pages, it can be helpful to include a list of manually specified “Best Bets,” triggered by business rules (Figure 7).8 This reintroduces the designer’s influence into search, smoothing out irregularities in the reliability of automated results.
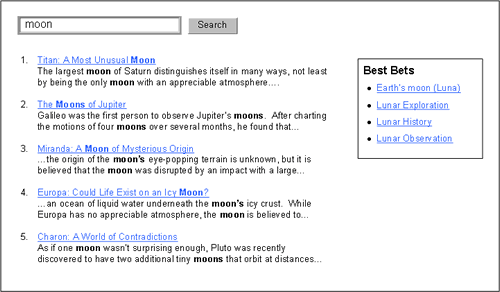
Figure 7. Best bets allow the designer to force particular pages to be returned when the user’s query contains a specific string.
Conditional Content
Taking Best Bets one step further, consider including contextually appropriate content in the search results page when a string in the user’s query indicates the user probably has a particular interest in mind. For example, a user searching for “extrasolar planets” on an astronomy website might appreciate a results page that includes a list comparing the properties of all planets discovered beyond our solar system.
Conclusion
This article introduces just some of the steps that you can take to improve the overall search experience on your site. The reliability of enterprise search needs significant improvement to reestablish user confidence, and IAs should take the lead. To get there, a product’s out-of-the-box functionality must not be seen as the end, but as just the beginning.
REFERENCES
-
1 Jared Spool: “BBC Reports Users Lose Patience with Poor Search”
-
2 Lou Rosenfeld & Peter Morville, Information Architecture for the World Wide Web, pp 136-137.
-
3 Fred Leise, Karl Fast, and Mike Steckel: “Creating a Controlled Vocabulary”
-
4 Tim Berners-Lee: “The Semantic Web”
-
5 Jared Spool: “People Search Once, Maybe Twice”
-
6 Christina Wodtke, Information Architecture: Blueprints for the Web, pp. 137-140.
-
7Lou Rosenfeld & Peter Morville, Information Architecture for the World Wide Web, pp. 188-189.
-
8 Chris Farnum: “Tuning up Site Search”
This is a great primer on search and its problems and ways to think about improving it. I’m curious if you’ve had any success with mapping specific problems you’ve observed back to one of the “5 variables”?
Great article. My company focuses on a complementary area – providing end users with a user friendly GUI, sitting “on top of” an OWL ontology – where “underneath” that, there are custom mappings to any/all corporate structured data, be that in Oracle, or any other rdbms, and other data files/flat files, excel spreadsheets etc, and data out on the web connected through web services. User Friendly GUI->OWL->SPARQL->RDF->Distributed Data. http://www.semanticdiscoverysystems.com
Good article, although I think you understate the effort involved in “create a taxononmy”! 🙂
I’ve also written similar recommendations in the past:
http://www.steptwo.com.au/papers/kmc_fixingsearch/index.html
Richard,
Yes, we have been able to map problems in search instances to the specific variables discussed above.
For example, earlier this year we conducted a search log analysis to evaluate the quality of results returned for the most common searches. A large number of queries needed to be discarded because we couldn’t figure out what the user wanted to find (the phrasings were commonly vague or oblique). That’s a user input problem; it would be unreasonable to expect that a computer would interpret the user’s intentions better than a human being could.
For queries where we were confident we understood what the user wanted, large numbers of seemingly irrelevant results were very common. The causes vary from query to query and result to result, and involve a complex interplay of content, index, and engine. But in many cases, a significant contributing factor could be found: the page had no metadata, the navigation was indexed, and so on. Again, any shortcomings of the engine cannot be easily resolved without disrupting well-performing queries, so the problem really has to be seen as one of the implentation.
Problems in the results display are easily observed in user testing. I’ve frequently seen the search engine return the right result, but the user skips over it because the meta description has no relationship to the query. It’s terribly tragic, because everything has performed exactly as it should but the user has no reasonable basis for knowing it.
I’ve seen these and other issues across a large set of evaluations, and they consistently map to one or more of the five variables.
James,
I imagine you’re referring to the section on ontology, and you’re quite right that it’s worth stating the task is nontrivial. That said, there are engine products that offer prebuilt upper and domain-specific ontologies, as well as a growing number of independently built resources available for purchase or public use. Modifying existing work would be much easier than starting from scratch.
Great article John. Especlally aorund user needs. many times with too much focus on getting technology to work we forget about the importance of delivering usefulness.
The use of meta tags for search engines is a little out-dated.
Most algorythmic search technologies (such as Google) place little value in the use of standard (or non-standard meta tags).
This is actually very positive and valid as content value is actually indexed on what the content ‘actually says’ (and references /links to etc) rather than what the author ‘says it says’.
I still work with content managers that think a well-stuffed meta keywords list will help their ‘searchability’ when in many cases it does nothing or actually works against them.
Indeed Google doesn’t use meta keywords at all anymore and the description tag is used only for result displays only.
Organisations would get far more value out of search by good valid mark-up code (as you’ve suggested) and well structured and organised user-focused content (i.e. using the language the users use for search terms), rather than relying on meta tags.
Generally meta tags are more useful for reference and overall orgsnaistion purposes for content authors rather than search engines and even then with the lack of a defined taxonomy (or even with one) this can quickly fall apart given that many organisations have widely distributed publishing with varying levels of meta-editorial or information structure concern.
In the end we need to consider content/site quality and the people processes that manage this content as much as the structures around the content as increasingly that is where search technologies are looking.
I thought the ontology part was interesting, and I often wondered how the search engine defined relevance in pages and well this article on how the search engine works, and parses the HTML for relevance enlightened me.
thank you for this information! This is something to think about!