Introduction
In a recent Boxes and Arrows article, Brett Lider and Anca Mosoiu describe how to build a “Metadata-Based Website.” They show how to use a centralized metadata repository as the basis of navigation for a website and explain how metadata makes it possible to “separate business concepts from the content or functionality about those concepts.” They suggest that, with this technique, enterprises can produce websites that enforce a consistent message, consistent user experience, and consistent reporting, while reducing the manual effort entailed when core concepts are represented in hard code or hand-crafted links.
We think the importance of a centralized metadata repository is a key insight. We’d go much further, in fact, and suggest that carefully developed metadata provides the foundation for a knowledge-model driven enterprise. This article describes how externally focused metadata is an essential element of a truly robust enterprise data model. It shows how a metadata repository can serve as a fundamental resource for enterprise applications of all kinds. And it argues for a wider role for information architects in designing and developing the kind of metadata required to serve such a broad purpose.
An Information Gap
Classic enterprise systems do a superb job of managing financial and transactional data, and of optimizing internal business processes based upon that data. However, in most organizations there is a great deal of highly important business knowledge maintained outside of structured database systems. Critical information is often embedded in documents such as catalogs, product literature, manuals, price lists, policy guides, engineering drawings, or organization charts. Sometimes it is built into business applications, websites, and reports, in the form of hard-coded business rules or manually maintained links. Many times it is simply not represented anywhere (other than in organizational memory and oral tradition).
One reason this happens is that some business knowledge, while extremely valuable, is not relevant to the optimization of business processes. For example, the operating parameters of a company’s products–temperature ranges, speeds, fuels, etc.–are often not recorded in any corporate database, mainly because such attributes are irrelevant to production or to any internal process.
A more fundamental reason is that much of the most valuable business knowledge is hierarchical, multi-dimensional, or network-like in nature, and therefore not amenable to representation in traditional corporate databases. Simple examples abound. To give one: in many companies, key information like “results by a sales team” can only be produced by spreadsheets, hard-coded reports, or accountants that address territory splits, multiple team memberships, sales manager overrides, and other aspects of real-world operations.
Broadly speaking, what’s missing from the classic enterprise data model is the outside world’s view of the enterprise and its data. This includes information that simply has no home in the traditional data model, along with more complex metadata that defines the structure, categorization, and relationships among business elements and concepts. This is a crucial gap! Without structured data to represent the external perspective, there’s no bridge between enterprise data and the non-experts who need to search, understand, and use it. Expert resources (such as salesmen or engineers) are required to complete even mundane transactions, and self-service is inconceivable.
And it’s a gap that must be closed, given today’s trends. The focus of enterprise software systems is shifting away from the traditional concern of Enterprise Resource Planning (ERP)–enforcing best practices within the enterprise–towards the much greater challenge of communicating effectively with customers, sales channels, executives, and others who drive process. The scope of the shared information environment now includes participants from the entire value chain. To support this transformation of focus, enterprises have begun to create fragmented islands of business knowledge in applications such as content management, Customer Relationship Management (CRM), and knowledge management. Without a single, integrated resource for business knowledge, inconsistency and duplication will increase, while the functionality offered by enterprise applications will remain limited.
Requirements
We argue that a centralized metadata repository offers the best way to bridge this information gap and to provide a consistent, reusable model of the external perspective on an enterprise. What are the principal technical requirements for the repository?
First, the repository needs to offer sophisticated modeling capabilities. After all, a significant objective is to represent complex relationships in data–the kinds of relationships that arise when human nature enters the picture. Some obvious examples have already been mentioned, such as the structure of a typical sales force and its relationships to products sold, markets served, and sales credit eligibility. In our view, the most powerful modeling approach is object-oriented, with the ability to define hierarchies, semantic networks, and other structures through connections among object instances.
The metadata repository and its modeling tools need to be designed for general-purpose application. Though some modeling capabilities are often present in knowledge management, content management, and other knowledge-enabled systems, these tools are generally built for a specific purpose and therefore limited by that application’s particular scope and requirements. Often they’re difficult to use outside the context of the application. To eliminate duplication of effort and promote consistency, metadata content must be easily repurposed and reused.
As a corollary, the centralized repository must truly be central. For the repository to achieve its goals, it must present a single, authoritative source of “the truth” that is readily available to applications throughout the enterprise. The fragmentation of knowledge models among a collection of front-office tools serves only to promote inconsistency and duplication of effort, and to compound findability and usability problems for information consumers. In our view, creating standards for the interchange of knowledge models does little to solve these problems, since the challenges of reconciling multiple, dissimilar models–each conceived for a specific purpose, and likely betraying differences of perspective–make the actual reuse of purpose-built models a doubtful proposition.
At the same time, metadata in the repository must be user-maintainable, mainly because skilled technicians are simply too limited a resource in the context of the sheer volume of relevant metadata. To make this possible, natural modeling techniques, simple terminology, and familiar user tools must be used in the construction of the repository.
Finally, it must be practical and efficient to use metadata from the repository in applications of all sorts–everything from websites to reporting systems to classic transactional applications. Technical barriers that prevent the metadata model from being used this broadly are unacceptable. Technical barriers that prevent the integration of the metadata model with existing enterprise data are also unacceptable. Ideally, developers throughout the enterprise should be able to incorporate metadata and enterprise data into applications using languages and tools they’re already familiar with.
Case Study
For us, these concerns are far from theoretical. During the last year we’ve been engaged in creating a Business Knowledge Modeling product that meets these requirements. The product is now functionally complete and has been deployed with its first customer (whose problems inspired the product in the first place). This case study describes the business problems we encountered with our first customer and the metadata solution we developed to address them.
The customer is a mid-sized manufacturer of industrial equipment with about 500 employees. Its catalog includes just over 60 major configurable product families, each of which is designed for a particular application, along with around 20,000 saleable off-the-shelf items (mainly spare parts). The products are described in the printed catalog and sales literature, and each product family has an associated documentation set. The products are also described and categorized on the website, along with links to relevant documents. Other vehicles that provide product information include a CD that brings together the catalog and documentation set, and an intranet site managed by the Engineering Department.
Business problems
This customer’s information environment presents a classic information architecture challenge: only an expert can reliably navigate all of the company’s product information. Obtaining relevant information involves using several different computer systems for different pieces of the puzzle, finding the right set of documents and the right content within those documents, applying oral tradition to bridge the gap between external documentation and internal systems, as well as occasionally using a scratchpad and calculator! As a result, a skilled salesperson or an engineer must be involved in virtually every customer transaction. From a business perspective, this means that transaction handling is inefficient, costly, and error-prone; customer self-service is simply impossible; and scaling the sales organization is extremely difficult.
The core challenge is simply that huge gaps exist in the company’s underlying data model. No single, authoritative database describes how the product set should be organized, classified, and presented to non-experts. No data anywhere describes the characteristics of the products and their models. No model of the company’s people, departments, and their responsibilities and relationships exists.
These issues are intensified by the transformation occurring throughout American manufacturing. Though the company’s manufacturing prowess was once its key strength, the company recognizes that its future success will be driven principally by its sales, marketing, and engineering abilities. As the company’s restructuring proceeds, the group involved in the selling process will grow substantially, becoming more geographically distributed and more culturally diverse. They’ll be selling and supporting a broader range of more complex products and services. Highly effective tools for the delivery of comprehensive information about the company’s products and organization will be required.
In short, a more modern information architecture–supported by a robust, centralized metadata repository that represents the external and organizational reality of the company–is an essential element of future competitiveness.
Metadata solution
An overview of the metadata solution we developed can be found in Figure 1. At its heart is an abstract model of the company’s product set. This consists of a detailed representation of the structure of product families, versions, and models, which until now has only been depicted in the text of the company’s marketing and product literature. A variety of information about these objects, including prose descriptions of the family or model, associated search terms, and product operating parameters, are stored as properties of each object instance.
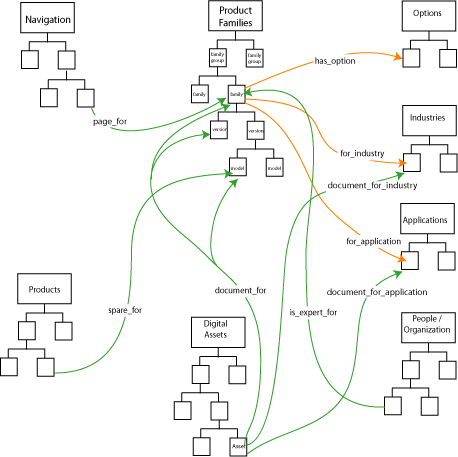
Figure 1. Overview of metadata model designed to support applications throughout the enterprise.
Separate hierarchies describe the variety of applications for which the company’s products are intended, the industries that use the products, and the service and packaging options. As shown in Figure 2, properties of product families and models relate them to the application, industry, and service hierarchies as appropriate.
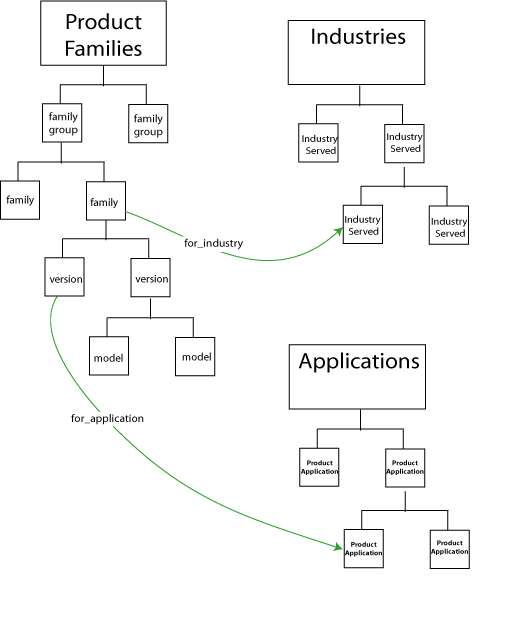
Figure 2. A faceted classification of product families is created using their relationships to industries and applications.
Another hierarchy drives user interfaces that navigate the product set (see figure 3). It includes descriptive titles and text for nodes in the navigation tree, pointers to images, and other data useful in constructing a user interface. Properties on leaf nodes of the tree point to resources elsewhere in the model–elements of the product family structure, for instance. This allows us to define and manage navigation of the product set separately from structures in which specific products are defined. It also provides for the possibility of third-party products, which might have external resources that define and document them.
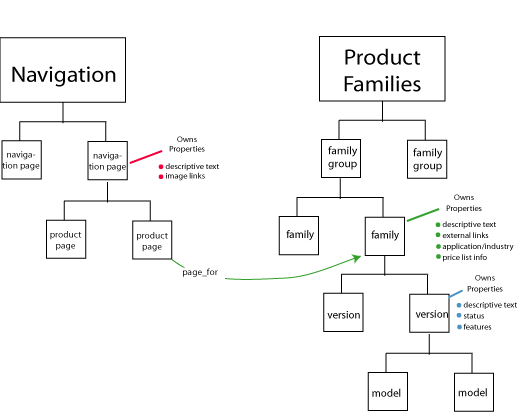
Figure 3. Navigation model provides an external perspective on the structure of the product offering.
Some metadata must be associated with individual part numbers from the enterprise system. For instance, the spare parts suitable for any given product model comprise a collection of relationships between individual part numbers and product model entities within the metadata. To serve this purpose, we add another hierarchy (depicted in Figure 4) organizing the company’s full set of 75,000 part numbers and providing a placeholder to link metadata content to underlying enterprise data.
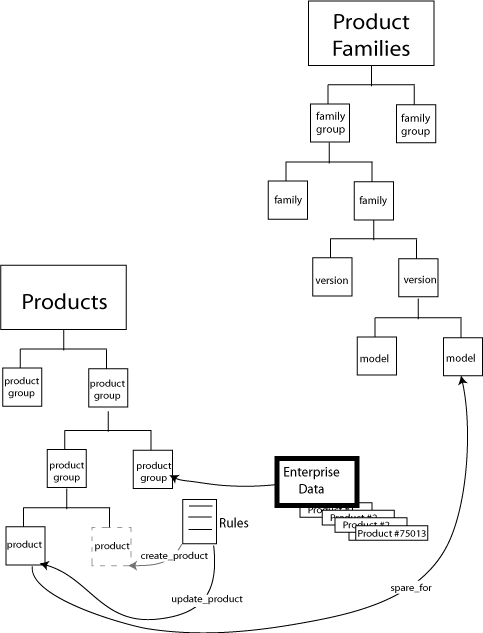
Figure 4. Relationships between enterprise data and elements of the model are required for effective use of metadata.
An automated process that runs nightly identifies changes to underlying enterprise data, instantiates new objects when necessary, and connects them to the hierarchy according to pre-defined rules.
A hierarchy representing the company’s organizational tree also appears at the heart of the metadata model. It has become apparent that a picture of the organization is a fundamental element of the metadata model, useful not only in itself but also in managing rights to access data and resources. Presently this structure is limited to the sales staff; future plans are to create a global model of the company. Figure 5 shows how access and expertise relationships will be modeled.
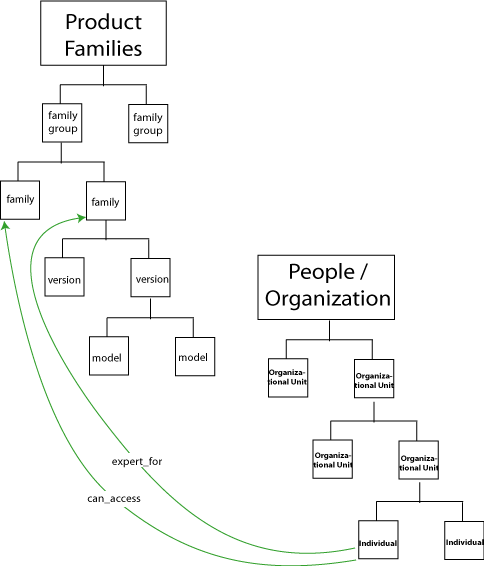
Figure 5. A representation of the organization structure allows access rights to be managed within the metadata model.
One other fundamental element of the shared information space is the collection of documents, images, and other digital assets that describe the company’s product set. A hierarchy has been defined to organize and categorize all digital assets (Figure 6), and we have integrated document and digital asset management into the metadata repository tools. Properties of digital asset objects point to products, models, and other instances to which they relate.
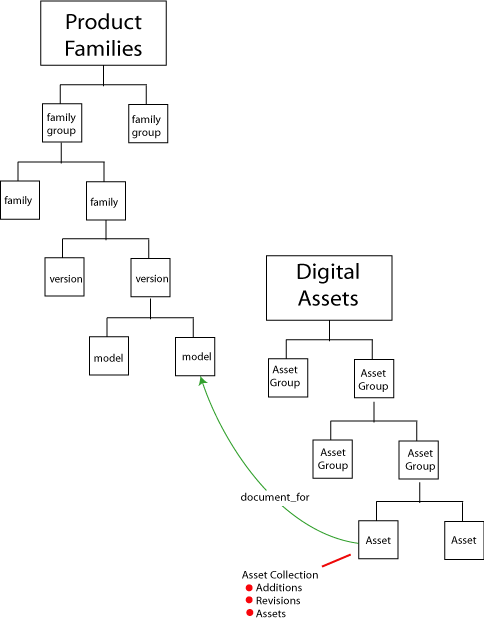
Figure 6. Integrated digital asset management supports immediate access to relevant documents, images, and other assets.
Applications
So how will all this be used? Current plans project that the following applications will be deployed within the coming year:
- Product catalog: A complete web-based product catalog system, including faceted classification (using the Navigation, Industry, Application, and Service hierarchies), text and parametric search, side-by-side feature comparison, and digital asset integration.
- Quote and proposal generation: Uses the navigation hierarchy for product search, the product family structure for comparative product data, and the organizational hierarchy for workflow. The quote tool is integrated with underlying enterprise data for price and availability. It features a product configurator that will also be modeled in the metadata system. Finally, it leverages the digital asset library to package proposals that include relevant documents, drawings, and other assets.
- Sales activity reporting and compensation management: Driven by the team structure, territory assignments, and relationships defined in the organizational metadata.
- Replacement parts: Draws on relationships between part number placeholders and product models to produce manageable lists of suitable replacement parts. Some options will be available only to approved staff, as represented in the organizational hierarchy. Integrated with real-time price and availability data.
- Engineering drawings: Provides edition and revision control and archive management features to the engineering staff, while allowing the management of the relationships between documents and the product families, models, or other entities they document.
- People-finder: Based on the organizational metadata, which defines department structure and reporting relationships within the organization and documents skills and responsibilities.
Return On Investment (ROI)
We believe that our customer will derive substantial ROI from these new, metadata-powered applications. Some of that return is tangible and will be easy to measure:
- Labor savings may be realized by eliminating duplicative software development and maintenance tasks. Substantial cost savings can also be realized through the reduction of effort devoted to the production and dissemination of literature such as catalogs, price lists, and manuals. Some website maintenance and content management tasks can also be simplified or eliminated, bringing further savings.
- Productivity improvements will be obtained by automating simple transactions, offloading tasks to less-experienced personnel, providing sales and service personnel with relevant information at the moment of need, and enabling self-service.
- Increased revenues can be obtained by improving flexibility and responsiveness to customers, ultimately enhancing their ease of doing business with our customer. Since sales effort devoted to handling simple transactions will be reduced, our customer should also benefit from increased sales focus and effectiveness.
The company will gain additional advantages that are a great deal more difficult to quantify, but may well be a great deal more valuable than the hard-dollar benefits. These include:
- Improved competitive position and increased customer loyalty through improved service to customers, channels, and distributors.
- Brand enhancement obtained by delivering leading-edge services and technologies to sales channels and customers.
- Significant strategic advantage and operational flexibility by capturing organizational knowledge in a sophisticated central repository.
- Reduced friction between organizations and enhanced scalability by simplifying and streamlining processes and removing scarce experts from common transactions.
- Elimination of some of the risk associated with ambitious software development initiatives that require sophisticated metadata.
Some Lessons Learned
Perhaps the most important lesson we’ve learned is that, as described in the previous section, real ROI may be realized through the deployment of metadata-driven applications. While ERP and other technology efforts have gone a long way towards optimizing internal processes, the way companies support and communicate with customers, sales channels, suppliers, and executives is still poorly automated and relatively inefficient. This problem is common to companies of all sizes, and substantial return on investment in knowledge modeling technologies is possible even in midsize companies like our customer.
The reason there’s an opportunity for real ROI is that the information gap in the typical company is surprisingly broad. In our work, we’ve been taken aback by both the extent and the importance of the information that’s not available in the existing enterprise data model. That’s good news, of course–it means there are numerous opportunities to deliver value using metadata-driven tools. But this rich field of opportunity creates a couple of problems of its own.
First of all, customer expectations can easily grow beyond what can rationally be delivered. The crux of this problem is that, while some metadata could generate ROI if captured, a substantial body of information falls more into the “nice-to-have” category. It is important to carefully analyze the costs and benefits of proposed metadata efforts to find those that offer real “bang for the buck.” It is also important to manage expectations aggressively to prevent customers from making unrealistic plans.
Careful analysis is especially important because the costs associated with acquiring and maintaining some metadata can be deceptive. Data volumes can be unexpectedly large, and metadata can sometimes be quite challenging to capture. It is easy to underestimate the investment required to populate a robust metadata model. So, once again, careful planning and expectation management are key.
Another potential stumbling block is the challenge of gaining consensus on very basic issues. At our first customer, for example, we were surprised to learn that there was no single, clear answer to the question “What is the structure of the company’s product line?” Project managers should factor in the time and effort required to put issues like these to rest, and should ensure that the right resources (in terms of facilitators, subject matter experts, and executives) are available to guide these efforts.
Reuse is fundamental to obtaining return on metadata projects. After all, a robust metadata model is inherently complex when compared with classic relational database techniques. In many cases, any single element of the metadata model could be represented more simply in standard normalized tables. It is only when models can be reused and integrated with other elements of the data model that the greater complexity of the metadata approach is warranted. Plans to acquire metadata should be made with a view towards the support of multiple applications that will use it.
From a modeling perspective, the basic concepts of the object-oriented paradigm have become familiar and instinctive to most end users. The use of taxonomies to organize and classify objects has also become intuitive, probably through the standard computer file-system interface. We have found that modeling techniques based on these elements are easily learned by non-technical staff. However, more advanced concepts from the world of knowledge representation are not comprehensible to the non-specialist. If non-experts are expected to maintain the metadata model over time, their skill levels and availability must be considered in choosing modeling tools.
Integration with relational data is critical. After all, that’s where enterprise data is found, and nearly all software developers have training and extensive experience with relational database products. Our metadata technology uses a knowledge representation technique based on relational technology, so that the interaction of our knowledge models with enterprise data is trivial. We have found the ability to use metadata to organize, summarize, and present enterprise data invaluable.
Conclusion
Knowledge models stored in a centralized metadata repository have the potential to deliver substantial benefits to the enterprise. A well-designed metadata model that accurately represents a real-world perspective is enormously valuable to a broad range of enterprise applications. In most enterprises a great deal of important information is not available in any structured database, so there are significant opportunities to generate ROI. And this applies to mid-size companies as well as larger enterprises.
Getting the modeling technology right is crucial, but it is only the first step in the process. The success of the metadata project depends upon a wise choice of data to model, careful design of the overall model structure, and a well-managed effort to gain consensus upon the actual metadata content. Customer expectations must be carefully managed throughout the process.
Information architecture disciplines are deeply relevant to these problems. A vision for the overall structure of the shared information environment is required to maximize value, as is sensitivity to the broad issues of organizing information for use by non-experts. Information architect techniques for analysis and consensus-building are also critical to project success.
We think the creation of knowledge models to drive the shared information environment represents an enormous opportunity for information architects, and a chance to extend their talents to enterprise-wide concerns that go well beyond website design.
![]()
I came across this article indirectly. I agree with its premise and have applied similar metadata management capabilities for quite a while. In the 1980’s I developed a methodology, metaschema, and supporting-technology specification for whole enterprise management. Over the years, I saw the terms “object modeling” and “metadata” come into form, and the technologies to support them. My approach to whole-enterprise management is at http://www.one-world-is.com/beam.
An excellent article, an interesting approach of building meta-models. I think it can be used in creating connection between several system within enterprise(company) such as CMS, CRM and other to provide better functionality & findability.
Andy, Thank you for a good article.
Best wishes,
Dmitry Semenov
web-Designer/Developer, Information Arhictect.
An article like this, which explores the sophisticated depths of professionally-designed metadata systems kind of begs the question: what about the really sloppy and dumb metadata systems that power content applications people really really love to use, like Flickr?
I’d like to see someone explain using del.icio.us style tagging with “real” content like the corporate knowledge base. Why not let someone enter both “product launch” and “prduct lnch” as tags in the same system without penalty? List them next to each other and any human can understand them.
Why do we assume that simple and dumb cannot work for our precious enterprise content?
Thisi article articulates a potentially very profitable business area. As is mentioned, one of the big challenges is to get organizations to define the structure and content of their product or service lines. This fuzzy area, which exists in all organizations, is the source of miscommunication and inefficiency and there are many benefits to addressing it. From a mgmt consulting perspective, it is difficult to pin down executives for definitions–they are reluctant to commit to codifying their systems, which are often driven by personalities and instincts. But a knowledge-based system such as the one described here can provide a strong foundation from which to launch creative and innovative efforts. A good article and a very promising opportunity for market growth.
Wendy Sydow
Proposal Manager
KEVRIC, an IMC Company
Good stuff … really good; haven’t been to B&A for a while and this reminded me of why it had been a regular favourite for so long.
For the past few months I’ve been exploring a paradigm that trumps metadata. User experience in the whole … dialogical, doncha know?
hfx_ben
While not a new concept, the information is well articulated and implementation of such a system is rare.
The authors list the advantages and constraints well. But the largest constraint towards the design, structuring and installation of such a knowledge warehouse is the transient nature of current the American corporate structure. Mergers and acquisitions throw a substantial roadblock in a very lengthy process.
Not to be the naysayer but other issues complicate the matter as well.
Changes in personnel and their rolls within the company provide a substantial challenge.
And lastly, building in an innate and organic growth capability into the system often cripples both the functionality and its usability.
All of that being said… kudos to Andy and his team for completing such a monumental project.