So what is free-listing good for?
Free-listing can be used to understand the contents of a domain. For example, a practitioner designing the information architecture for an online book vendor might need to generate a list of book genres and subgenres. Or the practitioner might already possess a list of genres, but need to verify that the list is exhaustive. Or the goal of free-listing might be to arrange the genres according to centrality or salience in the user’s mind.
Free-listing can also serve as a way to gain familiarity with user vocabulary for the domain. As a precursor to cardsorting, it allows you to define and limit the domain in question, and frame card items in the user?s own language. Apart from helping in all these situations, free-listing can also serve as a rough proxy for similarity methods, such as cardsorting.
Free-listing might seem similar to open-ended questions about subjective preferences, such as “What cars do you like?,” but there is an important difference when free-listing is used to explore semantic domains. The assumption with semantic domains is that there is something common to people’s understanding of that domain (i.e., user understanding is not completely idiosyncratic). Free-listing is a good way to explore that common understanding of the domain.
How to conduct free-listing exercises
Free-listing is a semi-structured method. It can be conducted as part of an interview, or as a written exercise (and can be done online as well). Simply ask the respondent, “Name all the x’s you know.” Give them sufficient time to do so. If they stop after very few items, encourage them by saying, “Can you think of any more?”
Of course, the first question is: How many respondents does one need? And, expectedly, the answer is: It depends. Note that if there was perfect agreement about the domain, then one respondent would be sufficient for the free-listing exercise (the same principle holds true for cardsorting). While you will never encounter perfect agreement about a domain, the logical corollary to this principle is that the more the agreement about a domain, the fewer respondents you need. For many domains, 20 to 30 respondents are enough to get a clear picture (Weller & Romney, 1988).
The best way to judge how many respondents you need is to look at your own data after you have run five to six respondents. Create a list of all items, sorted by their average rank (of being listed by a respondent). Examine how that rank order changes with the addition of each new respondent. If the ranks are relatively stable, then you can stop adding new respondents.
Salience, frequency and rank
Across respondents, some items will occur more frequently than others. This is because some items are more central (or prototypical) to the concept than others. For example, in a list of everyday animals, “cat” will be mentioned more frequently than “rat.” An interesting property of free-lists is that frequency of item occurrence across people is related to item rank (Bousfield & Barclay, 1950). Thus, the higher the likelihood of “cat” being mentioned in a list of everyday animals, the higher the position of “cat,” or the earlier it will be mentioned by an individual respondent. This indicates that frequency and rank are manifestations of the same underlying property: salience of an item (Romney & Dandrade, 1984). Thus, free-lists provide two related indices of the psychological salience of an item in a domain.
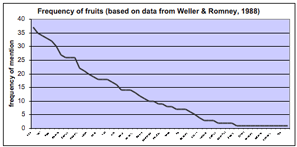 |
| Figure 1: Chart of item frequency |
Free-listing can help understand how a domain is perceived across a group of people by examining the average psychological salience of items. How do you know if an item is salient enough to be included and does not represent an idiosyncrasy of a particular respondent? One way is to list all the items according to their frequency of being mentioned. For most domains, the figure will be similar in shape to the one at right—a downward trend with a long spiral. For many domains, you will notice a long tail of items mentioned by only one respondent.
One way to decide what items to keep for the next stage of analysis is to identify any natural break points in the data. Or, use all items that are mentioned by more than one user.
All roads lead to similarity
Understanding the similarity matrix is crucial to understanding methods such as free-listing or cardsorting. The similarity matrix is the key data structure in going from user data to information architecture. Data-gathering methods can be direct similarity (rate the similarity of these two items or put all similar cards into the same group) or indirect methods (list all the items in a domain). Data from such exercises can be converted into a similarity matrix, which forms the input for analysis such as cluster analysis.
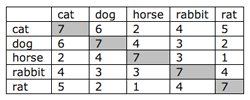 |
| Table 1: Similarity matrix |
A similarity matrix lists all the items in the columns and rows. The diagonal elements show an item’s similarity to itself. The top half of the matrix (above the diagonal) is the mirror image of the bottom half (below the diagonal). The number in each cell shows how many times two items were put in the same group. This similarity matrix is the input to cluster analysis in programs such as IBM EZSort.
Free-listing is not the best way to understand similarity between items, but there are two possible ways to compute similarity between items using free-listing data. Both methods should be considered an indirect index of similarity, inferior to other more direct measures such as cardsorting.
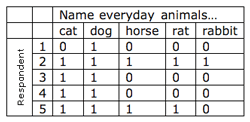 |
| Table 2a: Item by respondent matrix |
Co-occurrence: One way to find out if items are similar to each other is to calculate how many times they co-occur (Table 2a) (Borgatti, 1998). Consider cat and dog in the table below. They are mentioned in the same list four times. Compare this to cat and horse, which are mentioned in the same list only two times. If the data were analyzed through cluster analysis, cat and dog are more likely to occur in the same group than cat and horse. You can calculate such a co-occurrence metric for all pairs of items (Table 2b).
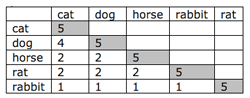 |
| Table 2b: Item co-occurrence (a type of similarity matrix) |
Average rank distance: Some research indicates that the closer two items are in free-lists, the more similar they are perceived to be (Henley, 1969). For example, in free-listing data, if cat and dog are mentioned closer to each other than cat and horse, then the first pair is perceived more similar to each other than the second pair. In order to examine similarity structured with free-listing data, you need to compute average rank difference for every pair of item. Note there might be little data for many pairs of items (this depends on how often a particular respondent mentioned both items).
Either of these measures—co-occurrence or average rank distance—will give you a similarity matrix (see Table 2b above), which can then be examined through cluster analysis in the same way that cardsorting data can be examined.
What else can free-lists tell you?
This is a general introduction to free-listing. There are many other ways to use free-listing data. Free-lists can be used to identify whether some respondents have more domain familiarity than others. It can also help isolate respondents who, for some reason, might perceive the domain in a completely idiosyncratic fashion. Such a respondent could make it difficult for you to identify trends and patterns shared by other respondents (especially in a small sample). A follow-up method that asks respondents to generate multiple free-lists (each item in the first free-list is used as starting point for others) can be used to further understand the structure of the content domain. Another usage is to compare the content and boundaries of two or more domains.
Summary
Free-listing exercises are easy to conduct. Researchers have noted that people find it a natural task. Because of this, it can be used with all sorts of populations, including children and illiterate people. Simple spreadsheet-based analysis can be used to answer many different questions. This method is useful both as a precursor to cardsorting, or as an independent method to create understanding of the content domain.
![]()
- Borgatti, S. (1998). Elicitation Techniques for Cultural Domain Analysis. In Ethnographer’s Toolkit, edited by J. Schensul. Newbury Park: Sage.
- Bousfield, W.A. & Barclay, W.D. (1950). The Relationship Between Order and Frequency of Occurrence of Restricted Associative Responses. Journal of Experimental Psychology.
- Henley, N.M. (1969). A Psychological Study of the Semantics of Animal Terms. Journal of Verbal Learning and Verbal Behavior 8:176-184.
- Romney, A.K. & DAndrade, R.G. (1964). Cognitive Aspects of English Kin Terms. American Anthropologist 66(3, Part 2):146-170.
- Weller, S.C. & Romney, A.K. (1988). Systematic Data Collection, Thousand Oaks, CA: Sage.
Hi Rashmi, It was interested to read your article. In fact, I want to know more about free-listing as I am thinking of using it for my qualitative analysis of fieldwork data. I have not found a good article talking about freelisting. Can you suggest something? B. Raj (http://www.nepalsathi.ws/)
All I can say is: brilliant. There are a whole bunch of research methods out there waiting to be discovered, adapted and put to use by the information architecture community. Excellent article!
I wonder if it would help or harm a cardsorting exercise to first conduct a free-listing exercise.
It is beneficial to have both free association and prompted association data, and to get it from the same participant, which saves money and time. I wonder if it would introduce a significant bias for the second, card-sorting portion of an activity.
Thoughts?
good point. IMO, using the same group of participants for both the free-listing and the card sorting exercise should not be a problem. A free-listing exercise will remind the user about their categorizations, but should not impact their categorizations in a way that will negatively impact the card sorting exercise. The reason being that categories and concepts develop over a period of time and are relatively stable.
But I do think that it might be difficult to do both free-listing and cardsorting in one session. If the purpose of the free-listing exercise is to generate items for cardsorting, then you need to finalize the list of items before beginning the cardsorting exercise. One possibility is to conduct the free-listing exercise via email, and ask the same participants to subsequently come in for the card sorting exercise. This would have the added advantage of letting you screen participants according to domain knowledge or some other criterion based on their free-listing data.
I wonder if one could conduct a group free-listing exercise. Ask a group of people, sitting around a table, to each write down a list of items in a domain. Subsequently, each person should read their list aloud their list. The second person should only read items not mentioned by the first person, and so on. In this way, one will compile one long list in the process of going around the table.
I have not tried this, but think it might work. What do you think?
I was thinking: to understand how they look at the domain “the web”, you could ask “List all the websites you know”. Or you could ask (and this feels like a better approach): “List all the types of websites you know”. I’m not sure. Any ideas?
Thats a tough one Peter. I spent quite some time thinking about this issue. On the one hand, free-listing can be used to enumerate items at any level in the hierarchy (so asking about either “websites” or “types of websites” is fine). But faced with a choice, I would go with “list all the websites” and then doing a card sort on the list that is generated. Research on free-listing seems to indicate that free-listing works very well when one is listing specific items. CNN.com and Google.com are specific sites that one has experience with, whereas Newssites or Search Engines are abstract categories. I think that free-listing will work better for specific items rather than categories. (My reasoning goes back to the differentiation between implicit and explicit memory. Explicit memory is tied to specific episodes and free recall tasks will tend to bring up such (explicit) memories. For example, when you think of the websites you have used for the past few days, you might remember making reservations on Expedia, reading about international politics on BBC.com and checking reviews of a digital camera on Epinions. This seems more likely than remembering making reservations on some travel site, checking international politics on some news site, or doing finding our more about a digital camera from a review site.)
Why does “list all the types of websites” seem like a better approach to you?
Sorry, I’m a bit late joining this. First, let me say a very provocative article for one who has recently decided to make card sorting techniques and tools a serious research endeavor. First, could you be a bit more specific about the method? As a cognitive psychologist, I’m generally familiar with the concepts and notions here.
Is this just a free association task? It seems to me that this is a classical situation where instructions make a huge difference. Rashmi, could you share a brief overview of one or two studies you’ve conducted, using Free Listing. Or do you have any reports you could share off-line via email?
I was recently introduced to the game “Taboo.” The object is to get your team mates to say a word without mentioning certain “taboo” words to give them clues. To take a simple example, if you wanted to make them say “birthday” you might not be able to use the words “happy” or “cake” as clues. Coming up with clues is quite a challenge since the best words always seem to be “taboo.” I wonder if the developers of the game used methods similar to those discussed in this interesting article.