Before delving into the details of how cognitive psychology informs information architecture, it is important to keep a few considerations in mind. The first is that psychological science is not “perfect” in the sense that all the significant variables influencing human behavior are known. Theories exist to be tested and disproved, so that more accurate theories can then be devised. A second consideration is that cognitive psychology focuses on theory and research, while the field of information architecture has tended more toward the practitioner side. A third consideration, perhaps the most important one, is that translating research results and theory to industry practice is, at best, an imprecise process. In fact, misapplication of research findings is a very real possibility—an example, given later, concerns misapplication of research on short-term memory.
Mental categories
From the user’s perspective, a mental category is a grouping mechanism, a way to bring together items or concepts through some unifying characteristic(s) or attribute(s). So what are those characteristics or attributes? This is where it gets interesting (and challenging) for the information architect because there are various ways to create categories and certainly no “right” set of categories to use.
In fact, from one user to another, the categories may differ significantly. Some categories are formed on the basis of visual similarity (e.g., this looks like a laptop computer, so it goes in my “laptop” category), while other categories could be based on items serving a shared purpose (e.g., software involved in web design). The items in a category could even be based on a set of rules for inclusion and exclusion (e.g., if there are no geometrical shapes, this cannot be a site diagram). Cultural differences, socialization, and cohort effects (differences based on when someone was born) also factor into the categorization process, creating even more diversity in how categories are formed.
Given that there are so many possible approaches to categorization, what is an information architect to do? The best advice is to try to accommodate as many different categorization approaches as possible, ideally supporting the most common approaches while realizing that accommodating everyone is impossible. In most cases websites just support one categorization approach for content, which puts the burden on the user to try to work within that approach. If the adjustment cannot be made, it is likely to be quite a frustrating experience. An example of this situation would be the use of categories specific to a given corporate culture; those outside the company would likely have a difficult time following the categorization scheme.
Open-ended card sorting is a very useful tool for studying mental categories and exploring why some categories are formed and others are not. Allow the user the freedom to freely sort the content cards, forming groupings and sub-groupings as necessary. If given the choice between sitting down with the user doing the card sort and taking notes, or letting the user complete the sorting using card sorting software, go with the face-to-face interaction. The software will likely perform a cluster analysis and reveal statistical groupings, but it is unlikely to record what the user said at a given moment, why groupings were made, or what groupings were perhaps created initially and then changed later. Those insights are invaluable when trying to understand mental categories.
Based on the card sorting, numerous approaches to categorizing the content are now apparent. How can these approaches be supported in the same interface? One answer is through the use of facets in browsing and searching. Both the Epicurious website and the Flamenco image search provide excellent examples of how a facet-based approach can be implemented. Search engines can also support this diversity of mental categories by clustering results based on facets. Of course, the trade-off here is that categorical metadata needs to be developed and applied to the documents, so significant time and resources must be available. The advantage, however, is that the users can now browse or search based on the facet closest to their way of mentally categorizing the content. Choice is returned to the user.
Visual perception
Visual perception also factors into the user experience because visual cues are often the basis for mental associations users make among items on the interface. The Gestalt psychologists explored how visual perception works, isolating a number of rules that explain how the human perceptual system functions. The two rules most pertinent to the Web are proximity and similarity.
The Gestalt rule of proximity indicates that items close together are perceived as being related/associated:

Proximity suggests two statements, not one.
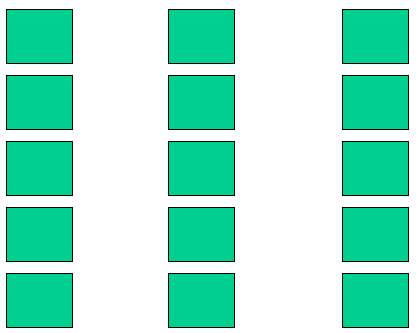
Proximity suggests three columns, not five rows.
The Gestalt rule of similarity indicates that items with a similar appearance are perceived as being related/associated:

Similarity suggests two statements, not one.
 Second and fifth rows perceived as distinct rows. |
The implications for navigation bar design are apparent, since navigation items that are across the page and appear dissimilar are unlikely to be perceptually associated. There are also important implications for the display of local navigation bars, which need to have their items be proximal and similar so that users perceive them as being together. They must also be associated with the appropriate section in the global navigation bar (and not be perceived as global navigation).
Most of your users should perceive the desired relationships if proximity and similarity are used appropriately. Wireframes and prototypes work quite well for testing your implementation of the Gestalt rules, providing low-cost options for improving visual design.
Memory
Memory is one of the primary domains examined by cognitive psychologists, since encoding, storage, and retrieval of information constitute a significant portion of our cognitive activity. Unfortunately, research done by cognitive psychologists on memory has not always translated successfully (or correctly) to information architecture practice. The best example of this is research on short-term memory, which established that humans can hold from five to nine chunks of information in short-term (temporary) memory.
Based on this research, some practitioners claim that navigation bars should not be longer than nine items. There are a number of flaws in this thinking. The first flaw, and the most important, is that global navigation is meant to be present on every page and that local navigation is meant to be present on every page within a given section of the website. Where is the need to commit the navigation bar to memory, if it is always there? Are users closing their eyes and trying to recall everything on the navigation bar? Of course not.
Another flaw is that applying the research to navigation bar length is akin to comparing apples and oranges; they are different settings. Navigating a website involves far more visual stimuli and interaction than the research tasks, and website content is familiar enough to fit into established semantic networks, unlike research content that is often random or nonsensical.
This is not to say that short-term memory (or other proposed players in memory processes, such as working memory) never comes into play. It just doesn’t come up based on the length of the navigation bar. Short-term memory becomes important when navigation bars disappear in the lower levels of a website, or when a link takes the user to an entirely different part of the website. At that point the user wonders: How did I get here?
And where is here, exactly? If navigation bars cannot be maintained at lower levels (perhaps because of interface constraints), short-term memory can be supported through the inclusion of breadcrumb trails, providing descriptive page title information and giving the page a descriptive and visually prominent heading/name. Efforts can even be made to visually denote a section of the website, such as using a certain color or graphic for pages within a section, which serves to remind users of their current location.
Excessive numbers of items in a navigation bar does potentially tax mental resources, but the issue here is one of information processing (not memory/storage) and the ability to visually scan and differentiate the “signal” (the desired item) from the “noise” (all the surrounding items). To reduce the noise, the use of headings in the navigation bar to group links is recommended. The Microsoft website uses such headings to good effect. Users can scan a smaller number of headings before scanning within a given grouping of links. Using this approach, navigation bars can grow comfortably to much larger sizes. Boldfacing the headings further supports scanning, as they “pop–out” from the surrounding links.
When a user is scanning through a list of links, trying to decide which one is best, that decision-making process brings in another type of memory: long-term memory. As the name suggests, long-term memory is storage for the long haul. Whether or not information is stored there permanently is still up for debate. Our problems remembering something could be because that information decayed and was lost, or it could be that the information is intact, but our ability to retrieve it is hampered by interference from other information. Whatever the case, our interest is in how memory networks are conceptualized. Those conceptual models give us insight into how users structure and associate concepts.
One approach to conceptualizing these is through semantic networks, or networks of meaning. Based on our experiences and learning, the nodes in these networks (which represent concepts or items) are linked together, forming an intricate network of interrelations.
As labels in the navigation bar are visually scanned, various nodes are activated in the network. Activation of one node triggers activation of connected nodes, which then trigger their connected nodes, spreading outward in a weakening wave until the strength of that activation is spent. This spreading activation helps explain how thinking of one topic can bring to mind related topics. Spreading activation also helps to explain how users struggle to decide between two or more navigation links that “both sound good” or who give up and say “none of these look right.” In the former case, the spreading activation patterns for the labels could have both seemed equally promising (they both activate the desired node at about the same strength), while in the latter case the desired node was never activated.
Closely related is the concept of information scent, as users could be evaluating labels based on their semantic networks, attempting to locate the label with the best “scent” (i.e., the label most closely related to the desired node in their semantic network). Card sorting is again useful in exploring (albeit in a limited and indirect way) the various semantic network structures established by users. Open-ended card sorts, where users freely sort cards into groupings and sub-groupings, help to establish which nodes are most closely interconnected. Closed card sorts, where users have to place content cards into predefined categories, help determine whether the information scent of the category labels is adequate, while also giving insight into how their semantic networks are structured. User testing is also extremely useful in determining whether information scent is correct and whether labels need adjustment.
Learning
A primary concern is with a little phenomenon called transference. No, this is not related to how you got along with your mother and how that influences current relationships. This is cognitive psychology, not counseling or clinical psychology.
Transference, in this context of learning, refers to our expectations about an interface’s behavior based on our previous experiences with other interfaces. How do we know the way a scrollbar works? That knowledge is based on previous experience. What do the icons in a toolbar represent to us? We make inferences based on our experience with other software that uses the same or similar icons. Trying to distinguish which navigation bar is global or which is local? We use what we have learned on previous websites to identify where those navigation bars tend to be located. If someone has to switch back and forth between Windows and Macintosh operating systems, sooner or later they will try something that only works in Windows on the Mac or vice versa, simply because of transference.
When our expectations turn out to be correct, the effect is one of positive transference. What we learned from the previous interface transferred successfully to the current one. Negative transference occurs when our expectations are incorrect; this process tends to result in an error. On websites, the transference typically involves layout choices, how links and buttons function, what certain labels and icons mean, and how technology used by the website functions. Websites with frames, for example, can pose negative transference issues, as users unaccustomed to frames may be confused about how printing functions and why bookmarking will only work for the homepage. In addition, the multitude of interface options offered by Dynamic HTML and Flash may be beneficial or harmful, depending on whether positive or negative transference occurs. Certainly, the effects of transference should always be considered in labeling and interface development.
A broadened perspective
Consideration of mental categories influences how content is organized, while factoring in visual perception, memory, semantic networks, and learning helps to guide labeling and interface decisions. Considering research and theory in cognitive psychology helps information architects create better user experiences, if only because it helps us ask more, and better, questions about what creates a good user experience.
![]()
Prior to entering the teaching field, he worked in industry as an information architect at a web design firm in Ann Arbor, Michigan. In his spare time he works as a freelance information architect and web designer.
Very good article! I think the most interesting point is visual perception.
Gigi
Hi,
Adding my thanks for the article. As a UX with a social anthro and copywriting background, the cog sci field often gives me the terminology I need to support my recommendations (everyone loves terminology right?) and this is a lovely summary of the key topics.
Transference is the area I often find most difficult to express – the notion that what your users have experienced before needs to be anticipated, and then those expectations either met or manipulated depending on your goal (there is a place for uncomfortable, challenging interfaces – just not many places).
More!
Excellent article Jason! Very, very relevant to IA – It would have been great if you could have expanded on some techniques to build semantic networks or mental models – maybe in the next article? 😉
– Richard
Very good article!… An article on mental models would be great! In my opinion is the paradigm clash (differences between mental models) the source of many many business problems… (and design issues, off course)
– Mark
These are very relevant and yet neglected issues.
I enjoyed reading this article and I would suggest to go further by exemplifying cultural determinants of perception.
In the perspective of design for all, this is a very important issue. Are there archetypes that can function basis for ellaborating rules of general (or broad) validity for enhancing adequate perception?
Clau
This was a great article! I think the most important point was the section on transference.
I find that everyone wants to be different when they design websites. Marketers don’t want “boring” labels that everyone else uses on their sites. People always want to break new ground when they launch a site.
I think that these people in the industry just don’t understand how important it is to use common GUI standards and guidelines in order to have a usable website.
A truely talented designer can utilize standard architecture and still have a unique or creative interface… that is the challenging part.
– Kyle
i don’t want to be the killjoy, but i have to say that i think that most of the article is actually pretty besides the point.
for everyone still believing that cognitive psychology is on a valid track about anything i recommend a good read in hendryk gedenryds excellent dissertation “how designers work”. it does a very, very thorough job in dissecting the claims of contemporary cognitive science, to the point where i get goosebumps (being a former cogsci devotee myself). you can find it by googling “how designers work” (don’t have the url ready).
regards
peter
ps: before flaming me, please give gedenryds work a look.
Spelling is: Henrik Gedenryd
URL: http://lucs.fil.lu.se/People/Henrik.Gedenryd/HowDesignersWork/index.html
Peter,
That’s a pretty tall order; asking dissenters to read a 200+ page paper prior to responding to your outlandish comment. I, for one, still believe that cognitive psychology is on a valid track in at least a couple of areas. For one tiny example, the effects of primacy and recency in remembering list items are well established, and applicable to all sorts of dynamic lists. However, I imagine that it is possible that this paper you’ve cited will challenge some aspects of cognitive psychology, and I will withhold further comment until I review it.
It better be good.
Hi Jason Withrow, hi everybody else here,
this is a great article, no question, especially, because the topic of my dissertation “ArchiText”, is almost exactly on this topic. So I have a few questions.
Does anyone have some good literature on this topic [especiall Gestaltpsychology and IA]? Or is this a brand new field of scientific investigation?
Are there a few other great websites concering topics like these?
Thanks a lot
Benjamin