I believe we all have a role to play in detecting, anticipating, and confronting the decisions that lead to breakdowns that threaten the organization’s very existence. In fact, the user experience function works closer to the real world of the customer than any other organizational role. We have a unique responsibility to detect and assess the potential for product and strategic failure.
There are many kinds of failure in large, complex organizations – breakdowns occur at every level of interaction, from interpersonal communication to enterprise finance. Some of these failures are everyday and even helpful, allowing us to safely and iteratively learn and improve communications and practices. Other failures – what I call large-scale – result from accumulated bad decisions, organizational defensiveness, and embedded organizational values that prevent people from confronting these issues in real time as they occur.
So while it may be difficult to acknowledge your own personal responsibility for an everyday screw-up, it’s impossible to get in front of the train of massive organizational failure once its gained momentum and the whole company is riding it straight over the cliff. There is no accountability for these types of failures, and usually no learning either. Leaders do not often reveal their “integrity moment” for these breakdowns. Similar failures could happen again to the same firm.
I believe we all have a role to play in detecting, anticipating, and confronting the decisions that lead to breakdowns that threaten the organization’s very existence. In fact, the user experience function works closer to the real world of the customer than any other organizational role. We have a unique responsibility to detect and assess the potential for product and strategic failure. We must try to stop the train, even if we are many steps removed from the larger decision making process at the root of these failures.
Organizations as wicked problems
Consider the following scenario: A $2B computer systems integrator provider spends most of a decade developing its next-generation platform and product, and spends untold amounts in labor, licenses, contracting, testing, sales and marketing, and facilities. Due to the extreme complexity of the application (user) domain, the project takes much longer than planned. Three technology waves come and go, but are accommodated in the development strategy: Proprietary client-server, Windows NT application, Internet + rich client.
By the time Web Services technologies matured, the product was finally released as a server-based, rich client application. However, the application was designed too rigidly for flexible configurations necessary for the customer base, and the platform performance compared poorly to the current product for which the project was designed as a replacement. Customers failed to adopt the product, and it was a huge write-off of most of a decade’s worth of investment.
The company recovered by facelifting its existing flagship product to embrace contemporary user interface design standards, but never developed a replacement product. A similar situation occurred with the CAD systems house SDRC, whose story ended as part two of a EDS fire sale acquisition of SDRC and Metaphase. These failures may be more common that we care to admit.
From a business and design perspective, several questions come to mind:
- What were the triggering mistakes that led to the failure?
- At what point in such a project could anyone in the organization have predicted an adoption failure?
- What did designers do that contributed to the problem? What could IA/designers have done instead?
- Were IA/designers able to detect the problems that led to failure? Were they able to effectively project this and make a case based on foreseen risks?
- If people act rationally and make apparently sound decisions, where did failures actually happen?
This situation was not an application design failure; it was a total organizational failure. In fact, it’s a fairly common type of failure, and preventable. Obviously the market outcome was not the actual failure point. But as the product’s judgment day, the organization must recognize failure when goals utterly fail with customers. So if this is the case, where did the failures occur?
It may be impossible to see whether and where failures will occur, for many reasons. People are generally bad at predicting the systemic outcomes of situational actions – product managers cannot see how an interface design issue could lead to market failure. People are also very bad at predicting improbable events, and failure especially, due to the organizational bias against recognizing failures.
Organizational actors are unwilling to acknowledge small failures when they have occurred, let alone large failures. Business participants have unreasonably optimistic expectations for market performance, clouding their willingness to deal with emergent risks. We generally have strong biases toward attributing our skills when things go well, and to assigning external contingencies when things go badly. As Taleb (2007)1 says in The Black Swan:
“We humans are the victims of an asymmetry in the perception of random events. We attribute our success to our skills, and our failures to external events outside our control, namely to randomness. We feel responsible for the good stuff, but not for the bad. This causes us to think that we are better than others at whatever we do for a living. Ninety-four percent of Swedes believe that their driving skills put them in the top 50 percent of Swedish drivers; 84 percent of Frenchmen feel that their lovemaking abilities put them in the top half of French lovers.” (p. 152).
Organizations are complex, self-organizing, socio-technical systems. Furthermore, they can be considered “wicked problems,” as defined by Rittel and Webber (1973)2. Wicked problems require design thinking; they can be designed-to, but not necessarily designed. They cannot be “solved,” at least not in the analytical approaches of so-called rational decision makers. Rittel and Webber identify 10 characteristics of a wicked problem, most of which apply to large organizations as they exist, without even identifying an initial problem to be considered:
- There is no definite formulation of a wicked problem.
- Wicked problems have no stopping rules (you don’t know when you’re done).
- Solutions to wicked problems are not true-or-false, but better or worse.
- There is no immediate and no ultimate test of a solution to a wicked problem.
- Every solution to a wicked problem is a “one-shot operation”; because there is no opportunity to learn by trial-and-error, every attempt counts significantly.
- Wicked problems do not have an enumerable set of potential solutions.
- Every wicked problem is essentially unique.
- Every wicked problem can be considered to be a symptom of another [wicked] problem.
- The causes of a wicked problem can be explained in numerous ways.
- The planner has no right to be wrong.
These are attributes of the well-functioning organization, and apply as well to one pitched in the chaos of product or planning failure. The wicked problem frame also helps explain why we cannot trace a series of decisions to the outcomes of failure – there are too many alternative options or explanations within such a complex field. Considering failure as a wicked problem may offer a way out of the mess (as a design problem). But there will be no way to trace back or even learn from the originating events that the organization might have caught early enough to prevent the massive failure chain.
So we should view failure as an organizational dynamic, not as an event. By the time the signal failure event occurs (product adoption failure in intended market), the organizational failure is ancient history. Given the inherent complexity of large organizations, the dynamics of markets and timing products to market needs, and the interactions of hundred of people in large projects, where do we start to look for the first cracks of large-scale failure?
Types of organizational failure
How do we even know when an organization fails? What are the differences between a major product failure (involving function or adoption) and a business failure that threatens the organization?
An organizational-level failure is a recognizable event, one which typically follows a series of antecedent events or decisions that led to the large-scale breakdown. My working definition:
“When significant initiatives critical to business strategy fail to meet their highest-priority stated goals.”
When the breakdown affects everyone in the organization, we might say the organization has failed as whole, even if only a small number of actors are to blame. When this happens with small companies, such as the start-up I worked with early in my career as a human factors engineer, the source and the impact are obvious.
Our company of 10 people grew to nearly 20 in a month to scale up for a large IBM contract. All resources were brought into alignment to serve this contract, but after about 6 months, IBM cut the contract – a manager senior to our project lead hired a truck and carted away all our work product and computers, leaving us literally sitting at empty desks. We discovered that IBM had 3 internal projects working on the same product, and they selected the internal team that had finished first.
That team performed quickly, but their poor quality led to the product’s miserable failure in the marketplace. IBM suffered a major product failure, but not organizational failure. In Dayton, meanwhile, all of us except the company principals were out of work, and their firm folded within a year.
Small organizations have little resilience to protect them when mistakes happen. The demise of our start-up was caused by a direct external decision, and no amount of risk management planning would have landed us softly.
I also consulted with a rapidly growing technology company in California (Invisible Worlds) which landed hard in late 2000, along with many other tech firms and start-ups. Risk planning, or its equivalent, kept the product alive – but this start-up, along with firms large and small, disappeared during the dot-bomb year.
To what extent were internal dynamics to blame for these organizational failures? In retrospect, many of the dot-bombs had terrible business plans, no sustainable business models, and even less organic demand for their services. Most would have failed in a normal business climate. They floated up with the rise of investor sentiment, and crashed to reality as a class of enterprises, all of them able to save face by blaming external forces for organizational failure.
Organizational architecture and failure points
Recognizing this is a journal for designers, I’d like to extend our architectural model to include organizational structures and dynamics. Organizational architecture may have been first conceived in R. Howard’s 1992 HBR article “The CEO as organizational architect.” (The phrase has seen some academic treatment, but is not found in organizational science literature or MBA courses to a great extent.)
Organizations are “chaordic” as Dee Hock termed it, teetering between chaotic movement and ordered structures, never staying put long enough to have an enduring architectural mapping. However, structural metaphors are useful for planning, and good planning keeps organizations from failing. So let’s consider the term organizational architecture metaphorical, but valuable – giving us a consistent way of teasing apart the different components of a large organization related to decision, action, and role definition in large project teams.
Let’s start with organizational architecture and consider its relationships to information architecture. The continuity of control and information exchange between the macro (enterprise) and micro (product and information) architectures can be observed in intra-organizational communications. We could honestly state that all such failures originate as failures in communications. Organizational structure and processes are major components, but the idea of “an architecture,” as we should well know from IA, is not merely structural. An architectural approach to organizational design involves at least:
- Structures: Enterprise, organizational, departmental, networks
- Business processes: Product fulfillment, Product development, Customer service
- Products: Structures and processes associated with products sold to markets
- Practices: User Experience, Project management, Software design
- People and roles: Titles, positions, assigned and informal roles
- Finance: Accounting and financial rules that embed priorities and values
- Communication rules: Explicit and implicit rules of communication and coordination
- Styles of interaction: How work gets done, how people work together, formal behaviors
- Values: Explicit and tacit values, priorities in decision making
Since we would need a book to describe the function and relationships within and between these dimensions, let’s see if the whole view suffices.
Each of these components are significant functions in the organizational mix, all reliant on communication to maintain its role and position in the internal architecture. While we may find may have a single communication point (a leader) in structures and people, most organizational functions are largely self-organizing, continuously reified through self-managing communication. They will not have a single failure point identifiable in a communication chain, because nearly all organizational conversations are redundant and will be propagated by other voices and in other formats.
Really bad decisions are caught in their early stages of communication, and become less bad through mediation by other players. So organizations persist largely because they have lots of backup. In the process of backup, we also see a lot of cover-up, a significant amount of consensus denial around the biggest failures. The stories people want to hear get repeated. You can see why everyday failures are easy to catch compared to royal breakdowns.
So are we even capable of discerning when a large-scale failure of the organizational system is immanent? Organizational failure is not a popular meme; employees can handle a project failure, but to acknowledge that the firm broke down – as a system – is another matter.
According to Chris Argyris (1992), organizational defensive routines are “any routine policies or actions that are intended to circumvent the experience of embarrassment or threat by bypassing the situations that may trigger these responses. Organizational defensive routines make it unlikely that the organization will address the factors that caused the embarrassment or threat in the first place. (p. 164)” Due to organizational defenses most managers will place the blame for such failure on individuals rather than the consequences of poor decisions or other root causes, and will deflect critique of the general management or decision making processes.
Figure 1 shows a pertinent view of the case organization, simplifying the architecture (to People, Process, Product, and Project) so that differences in structure, process, and timing can be drawn.
Projects are not considered part of architecture, but they reveal time dynamics and mobilize all the constituents of architecture. Projects are also where failures originate.
The timeline labeled “Feedback cycle” shows how smaller projects cycled user and market feedback quickly enough to impact product decisions and design, usually before initial release. Due to the significant scale, major rollout, and long sales cycle of the Retail Store Management product, the market feedback (sales) took most of a year to reach executives. By then, the trail’s gone cold.
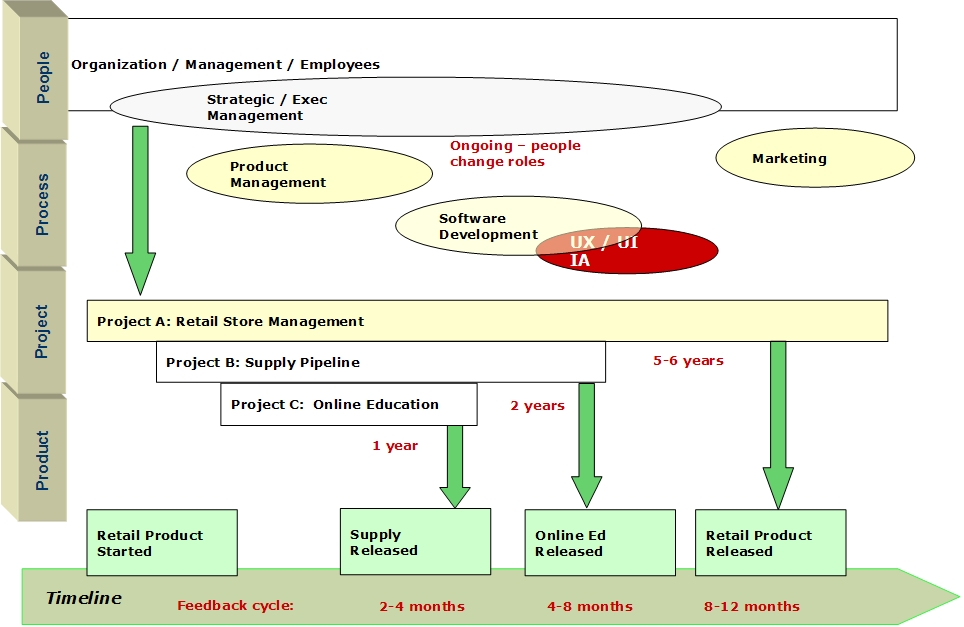
Figure 1. Failure case study organization – Products and project timeframes. (View figure 1 at full-size.)
Over the project lifespan of Retail Store Management, the organization:
- Planned a “revolutionary” not evolutionary product
- Spun off and even sequestered the development team – to “innovate” undisturbed by the pedestrian projects of the going concern
- Spent years developing “best practices,” for technology, development, and the retail practices embodied in the product
- Kept the project a relative secret from rest of the company, until close to initial release
- Evolved technology significantly over time as paradigms changed, starting as an NT client-server application, then distributed database, finally a Web-enabled rich client interface.
Large-scale failures can occur when the work domain and potential user acceptance (motivations and constraints) are not well understood. When a new product cannot fail, organizations will prohibit acknowledging even minor failures, with cumulative failures to learn building from small mistakes. This can lead to one very big failure at the product or organizational level.
We can see this kind of situation (as shown in Figure 1) generates many opportunities for communications to fail, leading to decisions based on biased information, and so on. From an abstract perspective, modeling the inter-organizational interactions as “boxes and arrows,” we may find it a simple exercise to “fix” these problems.
We can recommend (in this organization) actions such as educating project managers about UX, creating marketing-friendly usability sessions to enlist support from internal competitors, making well-timed pitches to senior management with line management support, et cetera.
But in reality, it usually does not work out this way. From a macro perspective, when large projects that “cannot fail” are managed aggressively in large organizations, the user experience function is typically subordinated to project management, product management, and development. User experience – whether expressing its user-centered design or usability roles – can be perceived as introducing new variables to a set of baselined requirements, regardless of lifecycle model (waterfall, incremental, or even Agile).
To make it worse (from the viewpoint of product or requirements management), we promote requirements changes from the high-authority position conferred by the reliance on user data. Under the organizational pressures of executing a top-down managed product strategy, leadership often closes ranks around the objectives. Complete alignment to strategy is expected across the entire team. Late-arriving user experience “findings” that could conflict with internal strategy will be treated as threatening, not helpful.
With such large, cross-departmental projects, signs of warning drawn from user data can be simply disregarded, as not fitting the current organizational frame. And if user studies are performed, significant conflicts with strategy can be discounted as the analyst’s interpretation.
There are battles we sometimes cannot win. In such plights, user experience professionals must draw on inner resources of experience, intuition, and common sense and develop alternatives to standard methods and processes. The quality of interpersonal communications may make more of a difference than any user data.
In part II, we will explore the factors of user experience role, the timing dynamics of large projects, and several alternatives to the framing of UX roles and organizations today.
I don’t have anything meaningful to contribute to this article, but as a Bostonian, I am excited by any use of the “wicked problem” terminology.
Too often designers stand aside when they see organizational problems, preferring to stay within the safety of the user needs/content venn diagram. But copanies are ecosystems, and sickness moves quickly from one part of the process to another; it’s dangerous to stand idly by. I’m happy to see this article so that more folks in the previously sheltered roles of designer/IA/IxD can learn what to watch for and how to speak up.
Great choice of topic – and some excellent insights into it. In particular, the magnifying effects of ‘organisational defenses’ are well-explained.
I do wonder about the ‘problem’ perspective, though, because it seems to me that (as with Bush and Iraq) often the tragedy is the result of ill-advised action in a complex situation. In a dynamic, reactive world perhaps we need to think of ecologies rather than problems.
Similarly, Peter’s observation that ‘good planning keeps organizations from failing’ seems based on an assumption that is worth examining. Maybe the success of ‘planning’ has more to do with informing the judgement of the actors than somehow controlling the situation?
David – I totally agree with your expression of organizations as ecologies rather than problems, in terms of dynamics. In terms of failures, organizations are wired up for self-defense, and their ecological network turns inward to defend itself from internal breakdown. A full ecological description is very hard to render as well, within a case study.
This is an attempt at an ecological description, while keeping it simple. That’s the point of the timeline figure, to illustrate interactions that occur between processes and projects. And it is still a fairly long, 2-part article at that! The second part may shed some more light on the inter-system interactions, by continuing with a case study.
Yes on your point about planning as well. The very act of planning helps the organization create artifacts that aid distributed cognition and maintain a series of anchors (in time and location) that inform participants about expectations and agreements. Like Eisenhower said “The plan is nothing. Planning is everything.” Creating insightful planning aids can lead to powerful consensus and commitment to action, perhaps to back up Christina’s point, an effective contribution we can make to organizational IA.
An excellent summary of the interaction (ahem!) between communication, organization and design. I find it a bold statement to suggest that IA can be the vanguard of organizational change. Not that I necessarily disagree but I have to wonder, where are the organization’s leaders? Where is the CEO or senior managers? And WHERE is the human resources department?
I think systematic distortion is part of the issue. Are we training our organizational leaders to distort information rather than shine sunlight onto problems? One could argue that this has always been the case, but is Peter suggesting that it is particularly bad “these days” and the IAs have a better eye or training to spot this?
An excellent summary of the interaction (ahem!) between communication, organization and design. I find it a bold statement to suggest that IA can be the vanguard of organizational change. Not that I necessarily disagree but I have to wonder, where are the organization’s leaders? Where is the CEO or senior managers? And WHERE is the human resources department?
I think systematic distortion is part of the issue. Are we training our organizational leaders to distort information rather than shine sunlight onto problems? One could argue that this has always been the case, but is Peter suggesting that it is particularly bad “these days” and the IAs have a better eye or training to spot this?
An excellent summary of the interaction (ahem!) between communication, organization and design. I find it a bold statement to suggest that IA can be the vanguard of organizational change. Not that I necessarily disagree but I have to wonder, where are the organization’s leaders? Where is the CEO or senior managers? And WHERE is the human resources department?
I think systematic distortion is part of the issue. Are we training our organizational leaders to distort information rather than shine sunlight onto problems? One could argue that this has always been the case, but is Peter suggesting that it is particularly bad “these days” and the IAs have a better eye or training to spot this?
Yes, Sam – I am suggesting that things are particularly bad, from my perspective. And there is distortion when people have something to gain. I’ve watched (and studied) North American organizational culture over a career that’s longer than I care to mention. And large organizations dealt with change and failure better in the early 90’s, for example, when the quality movement still ruled in many firms and “associates” were given lots of training, development, and respect. Team development, process improvement – these management trends, while pooh-poohed by many, helped create a more collegial environment than I observe in those same firms now.
Where is HR? Seriously downsized in many places, and lacking authority in most others. But the large-scale failures I’m pointing to are more ecological, and happen over time. They are wicked problems in that each mini-failure is just a symptom of another, and nobody has line-of-sight over the whole system. Decisions made in one domain (e.g., marketing) affect another (say, product development) with such a duration gap that there may be no opportunity to challenge the decisions once the impact starts showing up.
Why UX (rather than IA, really) can have an impact is that product design decisions can be tied to customer experience and real customer data. We can take a stand, over and over again, until other stakeholders realize the customer-centered stand makes good business sense. We don’t need our own C-levels to accomplish this – I’ve done this through a kind of socialization of UX practices through significant projects that build new routines in the organization. It takes time, but it builds highly resilient lateral decision networks. Some of this is in Part II.
Peter,
Excellent article. As someone who has spent many years at the sharp end of automotive quality it is nice to hear a good word said for the quality approach in organisations. I go back a long way and can still remember some of the incredible foul ups that used to occur before Quality was taken seriously.
Quality is still a very high priority in the automotive sector due to lean manufacturing and JIT (just in time) practices that must be adopted if automotive companies are to stay competitive. A failure in supplying any one of the 1000s of parts that make up a modern car could prove catastrophic. To that end the large automotive companies have tended to work very closely and supportively with their suppliers but have also insisted on suppliers using tools such as Failure Modes and Effects Analysis (FMEA) at every stage, Quality Function Deployment (QFD), capacity analysis, rigorous protyping and proving of all production processes before a single production part can be made. In other words the majority of the activity for any project is very much in the early stages and, in most cases in my experience, by the time you get to the first off production part its quite a straight forward process.
Do you think that this approach would have any value in the world of web design?
Looking forward to Part 2
Patrick
Nice preface. There’s the particularly juicy bit about organizations seeing pesky UX observations as a threat because of the common practice of time-boxing projects before an effort has been qualified across technology and customer experience.
One nagging reality that we deal with is accountability. A business stakeholder is usually on the hook for some sort of measurable performance indication specific to generating revenue or saving costs where the UX professional is not. As a result, the stakeholders relegate the UXers to the wrongly percieved role of “touchy-feely, non-business-savvy, navel-gazing designer-type”, or “clip-board carrying, out-of-touch-with-the-real-world intellectual” (See: Max Mayfield) making it easy to marginalize their input. “This isn’t your money we’re spending so it’s easy for you to say we need to re-think this!”
Because we don’t own the P&L statement for a business unit, we often find ourselves in an uphill struggle when it becomes clear (to us) that an application is on the wrong track.
This may be jumping ahead to Part II but I hope you have some ideas on how to increase the UX voice within the enterprise.
-AP
Nice article. I enjoyed reading it. Really informative, gathering organisational with user experience issues.
I particularly liked the approach of organisation architecture in realation to information architecture. Failure of major organisational projects is a situation nobody wants to experience but sometimes is inevitable.
Nevertheless I disagree with the figure 1 as it indicates IA / UX /UI as part of software development only, whether I believe IA / UX should be direct linked with people and product as well.
As already stated I am looking forward for Part II.
Marianna
It is too early to comment on the article as I am still waiting for the second part. However, I feel that preventing the failure of a product or organization is not our job.
As an IA our job responsibility is to bring in creative inputs for the product from user’s perspective. We must ensure timely addition of our inputs to the product development and fight for our cause when it comes to defend UXD process. But the success of a product or organization depends on many factors that are beyond the purview of IA. To try to address these factors is not a good idea as an IA as we are not trained for that. Let CEOs, Salesmen, and MBAs do their job and not encroach their territories.
In our language it’s like allowing a developer to do Information Architecture though he is not trained to do it. He is likely going to falter even if he tried to.
Our contribution for the success of the organization is to deliver our best and to fight for the users till the last drop of blood instead of starting doing something else.
However, it is a nice topic to debate about which is really evident from the comments that this article has attracted.
I’d like to post a couple of responses to the most recent comments. Thanks all for really reading the article – I was concerned of its length for B&A, and its more of an organizational studies article than a trad IA piece. Part II is up already now thanks to your responses! Marianna had contested the poisition of UX in the figure – I should clarify that the org processes indicated there are part of a real company in the case study, and are not in any way recommended for any other organization. But this is a traditional position for a large development company – and in this firm a weak position from which to promote organizational and product change. And, even as a small group without much authority, UX was able to assert real changes in the overall process across product lines through this organizational interaction style (not a method or process) we call socialization.
This also helps address Praveen’s comment. I guess it depends where you work and whether you take your job as defined in the organization, or are willing to take responsibility for helping push some of the changes that allow IA and UX to influence product strategy, marketing, and development. At this point, design decisions can be seen as not just user-centered, but as commitments from your firm to your users. Keeping a product healthy in the marketplace is everyone’s job, and as part of an organizational ecology, it takes a healthy organization to sustain a healthy product line in a competitive marketplace. Just like “innovation” is something everyone can do, standing up for the right decisions is part of our everyday jobs. There are also decisions that only we can see when they are happening, and they can reveal a lot. I’m just pointing out these types of organizational interactions from a real case to share some of how large-scale failure is a wicked problem that has no single cause, but we all have a part to play in detecting and raising the issues from our understanding as a situation emerges.
Hi again,
Thank you very much for the explanation. It makes better sense if I see this figure only as a case study for a specific type of organisation. I work for a smaller company and as a result, I am directly connected to the clients, users, designers and software developers; so I am closer to the product progress (which is mainly web sites) and I see that my decisions and advices can influence directly the development of the product. Furthermore, I absolutely agree with your comment that “Keeping a product healthy in the marketplace is everyone’s job”.
Marianna
Great writeup of the ideas you brought out in the failure panel at the 2007 IA Summit. I think it’s no accident that ecology is emerging as one frame to help us understand these complex dynamics at the organizational level. One natural – but not often explored – growth path for those with roots in UX / IA is toward the fields of organizational culture and development. Once you set aside the specifics of method (such as usability, information architecture), UX is essentially a perspective that provides practitioners with broad ways of approaching situations and problems. The mindset behind UX perspective is largely portable, and it can be fruitfully applied to domains such as organizational structure and planning. This is a pathway to traditionally business oriented disciplines like management consulting and business strategy. We may not all want to follow such a path, but it is a ready and well-trod road to more influence over, and involvement in, the bigger decisions we often see but cannot directly affect in a timely manner. The consulting boutique MIG (Management Innovation Group) made steps toward this a few years ago; some of their alums are still active in the UX community, and putting these things into practice daily.
When I was at Scient, a Fortune 100 customer proposed building their own version of Progressive insurance and their own comprehensive medical site for their employees to access within their benefit program. A top VP was supporting the idea and the project was supposed to have a big budget, we did not want to get sued for building an expensive application that no one would want.
We approached the lateral business owner/SME expert about testing the idea. .We conducted a Collaborative Usability Inspection (Lucy Lockwood) using a prototype in front of their business owner. From within their benefits application, the inspection had 2 representative users each walking through high-level goals of trying to get insurance for a teenage son and looking up medical information after being diagnosed with diabetes.
The business owner was initially frustrated when the users said that they would not look for that information within the benefits program. She clearly saw that the product idea was flawed and changed the model to linking to those sites. Since the tech bubble was about to burst, the idea of the next project was put on hold anyway.
Later, the business owner recognized the value of the Collaborative Usability Inspection concept, bought the book and took the class. She had been frustrated with getting management to listen to her and wanted to use the inspection to test her ideas.
This is an excellent topic to explore and discuss, because it happens often. I disagree with Praveen: as a paid consultant, it IS our job to be a good partner to the clients. Part of being a good partner is warning them (politely) that they are about to make a mistake, and to suggest alternatives. Those alternatives can be hardware, software, business processes, or even staffing or staff training. In my experience, clients often do not listen, but I try to go on record as saying “This may not be the best approach.” On one or two occasions, I’ve even let the client fail, and once, they even called back and said “You were right. Will you please come in and lay out your plan for us?” It was risky, but it worked. The point is not being right, but trying to do what is best for the client. Building that relationship and commitment to their business is good business for US, in the long run.