This article investigates content recommender systems. Because Netflix is probably the best known recommendation system and numerous articles have been published about their system, I will concentrate on their content recommendation mechanism as representative of the type.
I will show that the Netflix mechanism contains characteristics of updated theories of emotion—mainly constructed emotions theory—but it still lacks several essential components.
The lack of these components can explain some inaccuracies in Netflix recommendations and can suggest broader implications.
Emotions: A background
The traditional view of emotions (Paul Ekman
[1], as an example) is that people are born with a set of emotions—fear, anger, sadness, and the like.
Because we are all born with emotions, the traditional view is that these basic emotions are similar across all human beings.
Lisa Barrett’s recent research [2] has uncovered difficulties with this traditional theory.
One of the leading new theories is the constructed emotions theory. According to this view, emotions are learned, not born. Different people, therefore, have different emotions; cultural environment influences these emotions.
No emotion is universal, meaning some cultures have anger, sadness, fear, disgust, happiness and so on, and some cultures don’t.
The process of emotion begins in the brain. The brain tries to identify the physical environment, to understand what this environment has signified in the past, and what the cultural norms are related to this scenario. Following this analysis, the brain suggests an emotion most suitable to this context.
The context itself is also a factor; a different environment with identical traits would produce a different interpretation and thus a different feeling.
A simplified history of recommendation systems
A content recommendation area—such as Netflix’—shares general characteristics with the emotion analysis field.
With recommendations, we try to understand what the next thing a person would want to do or feel—such as when a person wants to feel frightened.
The prevailing opinion has been that as information accumulated by the recommendation system increases, accuracy will increase: More data, more accuracy. However, in the video recommendation field, the recommendations remain inaccurate despite the enormous amount of data available.
In a recommendation system, the system must analyze both the user and the content. My claim is that the main effort is focused on understanding the user rather than the content.
If we use the wrong method to understand what people want, no amount of data will make it more accurate.
Therein lies the problem.
User analysis
Theory of recommendations
The first generation of recommendation systems created a theory of recommendations; for example, if Thando watched sports content, Thando was probably a man and would want to see other testosterone-dominated content.

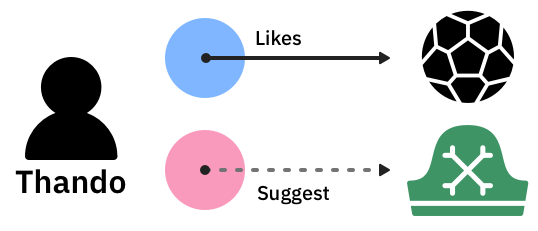
Then we discovered that women also love sports.
The second generation of recommendation systems used usage data and collaborative filtering and tried to identify preferences based on characteristics shared by different users.

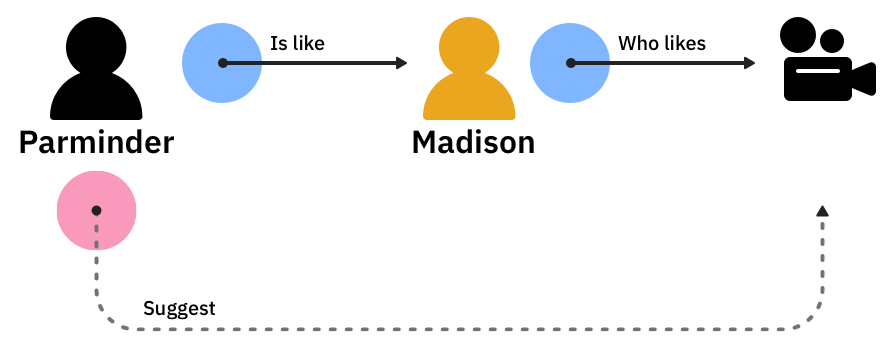
That is, if Parminder has characteristics like Madison, and Madison liked Movie X, Parminder would also love Movie X.
Theory without a theory
Today, we rely on behavioral and informational (such as registration or credit card data) correlations. These correlations are without a theory about the viewers. Here we will not claim that a woman, just because she is a woman, would prefer watching a soap opera.
This approach is called “theory without a theory.”
The “theory without theory” method does not assume global emotions. It seeks correlations between data without making assumptions about what the data represents, and hence these correlations do not represent any global emotion.

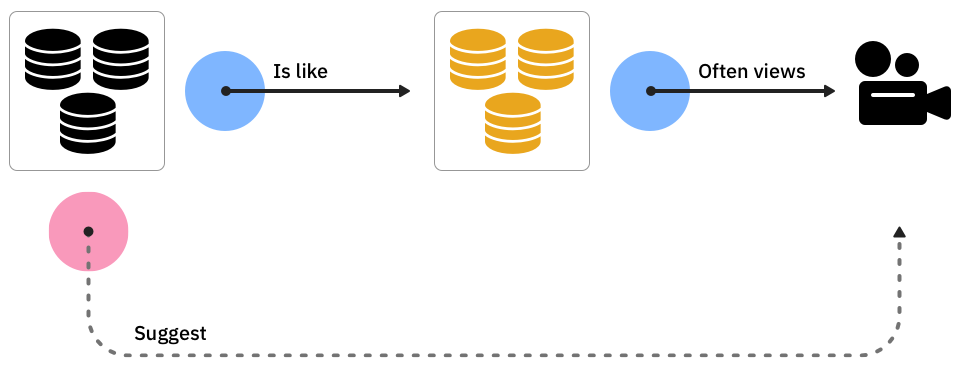
As in most AI systems—and advanced recommendation is an AI—the system has defined parameters that it needs to analyze. Defining the areas of analysis is a “theory of theory.”
For example, the inputs for the recommender algorithm include what time and day a view occurred (data) but does not include what happened to you offline before viewing and your physical location during viewing (context).
Thus, the system does not contain enough context, a point we’ll expand on below.
Content analysis
Now, back to Netflix.
Netflix content is defined by a team of about thirty people (“taggers”)[3], hired for their cinematic knowledge.
If taggers are hired based on their cinematic knowledge rather then their match with audience demographics, taggers cannot represent the diversity of the audience as they assign genres to movies. Some audiences will define Game of Thrones as fantasy, others as gore, and others in ways we can not think of. Thus, the Netflix taggers’ tagging is relevant to their own peer group and not to other groups.
It would seem that Netflix thinks that drama is a drama, but the updated theory on constructed emotion is that every cluster of viewers will define drama differently. The taggers are movie fans and their tags represent the emotional structure of American film fans—and not the entire population.
Building recommendations according to constructed emotions[a][b]
As stated, user analysis is a component that already contains characteristics similar to constructed emotions theory. It can be argued that people with the same socially constructed emotion is actually a correlative cluster and each correlative cluster is a subculture.
However, Netflix ’ recommendations are missing two components:
The principle of context deflection
The context of emotion changes the emotion and perception. You perceive what you believe.
An example is trying to analyze people when you are hungry. Usually hungry people, before a meal, will find other people more annoying. Why? Because the hungry person is more agitated.
My subjective interpretation of the behavior of another person is based on my belief system and context. Interpretation is projection.
Context deflection is the location, the mood, and the content—among other things—the person consumed before the recommendation. As an example, my preferences are likely to be different at work, right after work, and in a resting environment. Recommendation systems need to account for this deflection, because the context alters my emotion and the way I read other people’s emotions. The system should understand my environment of feeling—whether I am hungry and edgy or fullfilled after a good day at work.
The context alters my emotion and the way I read other people’s emotions.
Recently, Netflix has added an analysis layer that relates to events, such as an Olympics. This is the first step in the calculation of deflection. However, this stratum seems to be universal (tagging as usual) and does not relate to subculture.
Content analysis
Content analysis is the study of how the viewer experiences the content and what emotion a specific program causes to a specific viewer.
Systems today know how to analyze which people feel the same way—for example, people for whom “fear” has the same meaning. But, systems do not analyze how different people experience different content. The system might tag content as “fear” without considering the fact that “fear” might mean different things for different people.
As an example, certain people will define “Jessica Jones” as a comedy presenting a strong woman role[4]; others will define it as a show about a woman dealing with post-rape trauma.
Just as there are difficulties in diagnosing a person’s emotional state (since there is no “fingerprint” of emotion), it is difficult to know how a person experiences content.
A new approach to recommendation systems
Based on all the above, we can suggest a new approach to recommendation systems that is based on two algorithms: user definition and content definitions.
User analysis algorithm
This algorithm bears similarities to existing systems but puts more emphasis on deflection.
- First, we should collect as many parameters as possible, even if their relevance is unclear. Among the data we get could be location, browsing before recommendation, viewing before recommendation, page duration, etc. Based on the data, we can generate behavior clusters / subculture to which the users belong.
- Then, we tag users. Based on the user’s collection and user’s content selections, the system will label each user as belonging to a subculture cluster (artistic film enthusiasts at work). This tagging will serve as the basis for content matching.
- Finally, we forecast. We will try to find forecast correlations between content labels (see below) for subcultures. For example, if cluster A tends to group content tagging B in the X environment, we will recommend content containing tagging B.
Content analysis algorithm
The content analysis is the part in need of a dramatic change. We suggest here a subculture-based content analysis.
Today, Netflix content is globally tagged; all viewers around the world have had the same tags applied to Game of Thrones. The change we propose is that each content be labeled separately by representatives of different subcultures that are defined by viewers’ cluster analysis.
To clarify: Commercial bodies analyze cultural groups in mass media based on demographic/social groups, such as urban Asiatic males with above-average income.
Our proposal is to analyze based on subculture groups: Manga viewers during work hours, as an example.
Netflix analyses show that the recommended correlation of an interest group (“manga”) is higher than that of a national group (“Canadian”). Although the Netflix claim has not been reviewed academically, it confirms the constructed emotions theory. Cultural groups should be the base groups for comparison and not national, social, or demographic groups.
Conclusion
In this paper, I tried to present a new structure to recommendations based on the constructed emotions model. The structure contains a few fundamental changes:
• Expanding the user’s specific analysis, gathering as much information as possible on the user
• Based on the previous point, identifying the deflection of the person
• Creating content tags based on the subculture to which each observer belongs.
Although Netflix seems to be aware of the first two points, the third point has thus far escaped their notice, to the detriment of the audience.
Cultural implications
Changing the perception of the Netflix recommendations mechanism also constitutes a change in social/cultural perception.
At least for the Netflix user subculture, accessible global content and less local/national/state content has dramatically changed the nature of cultural influences. Some 20 years ago, the gap between global and local content was broad, and accordingly the cultural platform was local and mainly national.
Traditionally, we used to define ourselves by nationality/society group: “I am American, Texan, Christian.”
In the case of emotional analysis and recommendations, it seems that the correct self-definition is “I am a fan of manga during work hours.”
Remember the constructed emotions theory: Emotions are learned, not born. Different people therefore have different emotions; cultural environment influences these emotions. As video content becomes more dominant in our daily life, it becomes more influential on how we develop our emotions. As the content offering becomes more varied, the differences in emotion sets for the same geography becomes wider.
The change in the distribution of mass content has brought a change in global subcultural groups and thus in the global system of emotions.
My suggestion is that to have better prediction of viewer datasets, recommendation-based companies should involve the users in the tagging process of content. Don’t build a team of content taggers or analyzers: Ask your viewers to define the content. As is often the case in technology, the old way—in which people define rather then experts and algorithms)—is the more advanced.
Endnotes
Special thank to Dr. Ehud Lamm of T-A University for guiding me in my original paper on this topic and Anna Belogolovski for Data science background
[1] Ekman, P.; Friesen, W.V. (1971). “Constants across cultures in the face and emotion” (PDF). Journal of Personality and Social Psychology. 17: 124–129. doi:10.1037/h0030377. PMID 5542557. Archived from the original (PDF) on 2015-02-28. Retrieved 2015-02-28.
[2] Barrett, Lisa Feldman. How Emotions Are Made: the Secret Life of the Brain. Mariner Books, 2018.
[3] Grothaus, Michael. “How I Got My Dream Job Of Getting Paid To Watch Netflix.” Fast Company, Fast Company, 28 Mar. 2018, www.fastcompany.com/40547557/how-i-got-my-dream-job-of-getting-paid-to-watch-netflix.
[4] https://www.usatoday.com/story/life/tv/2017/08/22/you-wont-believe-what-shows-lead-viewers-watch-netflixs-marvel-series/587947001/
what a brilliant piece of analysis – highly recommended for anyone seeking to understand recommendations engines and content.
Thanks for sharing. Do you have any real application of this supposed new algorithms?
the paper presents a model companies can try and adopt. working with some content services it seems applicable to their model. to the best of my knowledge no company is currently using this method
highly recommended for anyone seeking to understand recommendations engines and content.