The Problem
Okay, I’ll admit it. I’m hopelessly disorganized in my digital life. My inbox is overflowing with email. My documents are scattered across a half dozen hard drives, none of them backed up. When I recently needed an up-to-date resume, I had to write it from scratch, because I couldn’t find a copy anywhere.
Most people would say that it’s my own fault. It’s true; I should take greater care in organizing my data. But honestly, I’m just too lazy to spend the time to sort all my files into the proper folders. And I’d like to think that I have more important things to worry about than when I ran my last backup.
There’s an old adage in software development that says laziness is a virtue. By laziness, we mean only avoiding unpleasant work. For a programmer, the most tedious work to do is work that could be done by a program. Rather than spend an hour on a repetitive task, a programmer will spend 59 minutes writing a program to complete the task in 30 seconds. As Abraham Lincoln said, “give me six hours to chop down a tree and I will spend the first four sharpening the axe.” In the same spirit, I justify my laziness because I think software should do most of the work of information management for me.
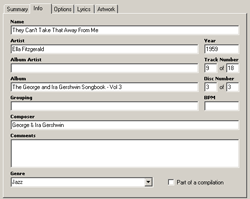 iTunes uses formal metadata fields |
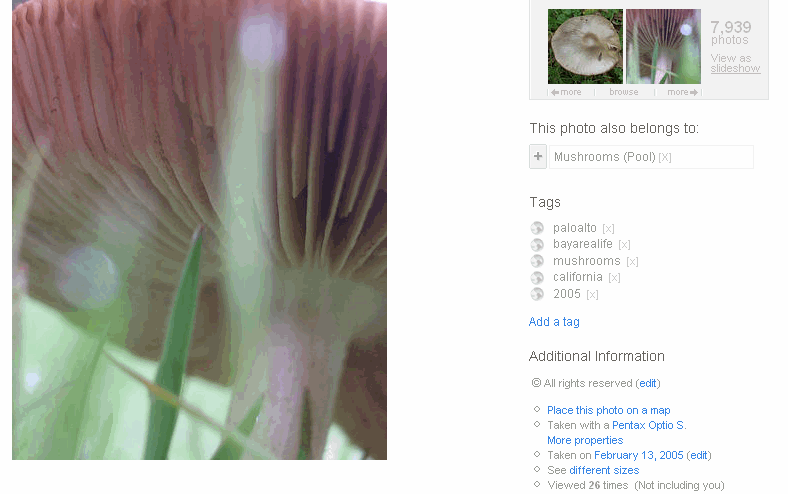 Flickr prefers freeform “tagging” Flickr prefers freeform “tagging” |
There are plenty of great information management tools out there. Certainly, iPhoto has made it easier to organize my digital photos. Flickr and Del.icio.us have popularized tagging—organizing items by simply marking them with keywords—and created a new way to navigate large amounts of data. And iTunes is a definite improvement over manually organizing MP3s into folders.
But as helpful as these applications are, they can be frustrating to use, because each one implements a slightly different set of features, even though they are basically solving the same information management problems. For example, iPhoto allows you to tag a photo with keywords, but iTunes doesn’t allow you to do the same thing for a song. Subtle incompatibilities like this can contribute to a frustrating user experience, because the interface doesn’t behave like you expect it to.
Even worse than slight incompatibilities between applications, is that they often support entirely different data models. In The Design of Everyday Things, Donald Norman explains that when we use a tool—like a drill, a car, or a computer application—we have a mental model in mind of how the tool works, and how it will react to our actions. This mental model guides how we use the tool. With so many different applications to manage our data, we have to keep track of several different data models, and it’s easy to get confused. For instance, when I’m browsing my photos, I might see a photo that I want to send to a friend. In both Picasa and iPhoto, I can click a button that allows me to email the photo to them. But I can’t do the same thing with a song in iTunes, or a bookmark in Firefox. What’s so different about each of those things? In my mental model, they are all just objects that I want to send to my friend. Unfortunately, this data lives in a balkanized world, and what we are allowed to do with the data depends on what form it is in.
This balkanization of our data also makes it more difficult to find things. Before being able to search for something, you have to know what form the data is in, so that you can search in the right application. Did I store it as a Del.icio.us bookmark? Did someone email it to me, or was it in an instant message? Applications like Google Desktop and Apple’s Spotlight help address this problem, but they support a limited number of data formats, and they aren’t able to search across multiple machines.
Another usability problem occurs when trying to share data between applications. A really simple example: my friend Ryan asks me to email him the photos from our last trip to Mt. Washington. I have no problem finding the photos in Picasa, because I’ve got an album called “Mt. Washington Trip 2006”. I can open the album and browse through thumbnails of the photos, looking for that great one that I took from the summit. But when I try to email it to Ryan from my Yahoo! Mail account, I have to browse through the file system to find the file. Even though I have the photo up in Picasa—Right there! That one!!—I can’t communicate that in an intuitive way to the web browser. Luckily, I know how to map from a photo in Picasa to the corresponding file on disk, but many people would not. Picasa provides a great abstraction: instead of thousands of files with unintelligable names like IMG_1792.jpg, it lets us work with the pictures, captions, and albums. But Picasa’s abstraction is like a dialect private to an isolated town: as soon as we leave, we are forced to use the computer equivalent of grunts and hand signals.
All of these problems are caused by the fact that by using many different specialized applications for personal information management, the data is segregated based its form. Using the term segregated isn’t an exaggeration—in some ways, the data is literally not allowed to mix together. For example, I’d like to gather a digital scrapbook of my trip to Europe. It would have emails that I sent and received during the trip, contact information for the people that I met, bookmarks for various places that I stayed, and of course, lots of digital photos. On most systems, this is difficult, if not impossible. It can be done in a crude way by copying some files into a folder and cutting and pasting into text files. But then I would lose all the features of the specialized applications, like captions on the photos.
In short, I believe that there are several usability problems caused by the fact that we use many different specialized applications for managing our data. We can become frustrated and confused by incompatible data models and inconsistent features. It’s harder to find the information we are looking for, because we have to remember what form the data is in. Communication between applications is awkward because they don’t speak the same language. The data is stuck in silos, segregated by its type. This prevents us from using perfectly natural ways of organizing our data.
Towards a Solution
Now that we’ve established what the problem is, the question is: what can we do to fix it? Obviously we can’t expect to have a single application which will support all of our needs. We still need specialized software like iPhoto for managing photos, and GMail for email. I think that the problem is not really with the applications themselves, but with the platform they’re built upon.
In software terms, a platform is a collection of common routines, and a set of interfaces allowing applications to use the routines. Normally, an application is built directly on the routines provided by the operating system. Developers and designers have long understood that an inconsistent user interface is difficult to use, so the UI is built into the platform, resulting in applications that mostly look and feel the same. In order to achieve the same kind of consistency with information management features, we need a platform designed for the manipulation of rich information.
While the amount of information that the average person deals with has increased dramatically in the last 20 years, file systems have hardly changed at all. All modern operating systems do in fact provide a common way to manage information: the file system. Unfortunately, while the amount of information that the average person deals with has increased dramatically in the last 20 years, file systems have hardly changed at all. We are still stuck with the old file and folder model. The problem with this model is that an increasing amount of data just doesn’t fit into it. For example, a single email usually does not correspond directly to a file on the local disk. Another example is bookmarks—many people collect and organize hundreds of bookmarks, but a bookmark is not a first-class object like a file.
In a broad sense, this new information management platform that I am proposing is really just a new kind of file system, based on the needs of today’s users. We need a system that will make it easier to manage and navigate the large amounts of rich and diverse information that people deal with every day.
In the first part of this article, I identified five distinct usability problems, all caused by the fact that we use many different specialized applications for managing our data:
- Inconsistent features between applications
- Incompatible data models
- Difficult to find data, because we have to know where to look based on the type of the data
- Awkward to share data between applications
- Inability to mix different types of data together
In the same way the user interfaces are much more consistent because applications all use the same toolkits, then having a common information management framework that other applications can build upon will go a long way towards a more consistent set of interactions. I’d like to outline what I think are the key requirements for such a framework to be successful.
Requirement 0: Be a useful and usable framework
Only if it’s actually used can an information management framework help solve the problems I’ve identified here. The framework must be easy for application developers to build upon, and it must be useful enough to be worth their effort. By building on this framework, application developers would be able to focus on the core functionality of their applications, rather than wasting their time reinventing common information management features.
Requirement 1: Extensible for new kinds of data
By having applications build upon this framework, we eliminate the problem of having incompatible data models. But the platform must be extensible to be able to handle new types of data. The reason that we have to deal with the different data models of specialized applications is because the existing platform (the file system) was not suited for managing the rich data that today’s applications require. If the framework I’m proposing is not built from the ground up to be extensible, we will quickly find ourselves in the same situation we are now: trying to do today’s job with yesterday’s tools.
Requirement 2: Comprehensive search capability
The third problem I identified was that it’s difficult to find data, because you have to know where to look depending on what form the data is in. If it’s in an email, you have to search in one place, but if it’s in a file on your hard drive, you have to search in another place.
While search is not the answer to all our information management problems, it is a very useful feature. Now that Google is a verb, most people are comfortable using search as a primary way to find data. A new platform for information management should provide advanced search capability. Apple has done the right thing by building Spotlight’s sophisticated search functionality into the operating system, and allowing applications to build upon it.
But in order for search to be truly effective, we need to be able to search all of our data at once, instead of having to search in each of the individual silos. Having a single framework for managing rich information means that it will be able to search through all different kinds of data, no matter what form it takes.
Requirement 3: All data on equal footing
One of the problems I identified with current information management systems is that it’s difficult, if not impossible, for different types of data to be mixed together. You can’t create a folder that contains an email, a photo album, and some bookmarks. This problem is also related to the problem of inconsistent features and data models. Things that can be done with one type of data, like a file on the file system, can’t necessarily be done to other kinds of data.
In other words, there is an artificial distinction between different types of data. What a bookmark, an email, and a text file all have in common is that they are distinct, discrete pieces of information. If the purpose of the file system is to allow the user to store and organize information, then it should be able to treat these kinds of items equally. All types of data must be on equal footing. Anything that can be done with a file—like copying, searching, or sorting—should be possible with other pieces of information. If all data is on equal footing, then it would be possible to have a folder containing several different types of data.
Requirement 4: Flexible organization features
The folder (or directory) is the most common organizational metaphor used on computers. Originally, this concept was designed to be analogous to a physical file folder, so a document could only ever be in one folder. But it often makes sense for a document to be in two different folders at the same time. For example, if you had tickets to take a client out to a hockey game, should you put them in the “hockey” folder, or the “work” folder?
In information architecture, it’s good practice to support several paths to a piece of information. This is generally because we need to support many different users, who might have a different mental models. But even with a single user, there are sometimes several different mental models involved. Just today I went looking for my wallet, and couldn’t find it anywhere—although I’m sure I put it somewhere that made sense at the time.
The idea that an object could exist in multiple folders is known as multiple classification, and it has recently become popular in the form of tags. Flickr, Del.icio.us, and many other web services allow you to associate several keywords with your data. By doing so, you are indicating that the data falls into various categories, with the idea that this will help you or someone else more easily find the data later.
Providing support for multiple classification is just one example, but in general, for a new information management platform to be successful, it must be flexible enough to allow you to organize your data however you want.
Conclusion
In the first half of this article, I identified several usability problems with the current state of information management software. We use many different specialized applications for dealing with different kinds of information, and the applications have inconsistent features and incompatible data models. It is harder to find our data, because we need to know what form it is in, so that we can look in the right place. It’s awkward, and sometimes impossible, to share data between applications, and to mix the data together outside of the specialized applications.
To solve these problems, I proposed a platform that could be used to build the next generation of information management applications. Having a common platform for developers to build upon would give us greater consistency between applications—they would have the features we expect, and these features would work in the same way. Integration between applications would be much easier, as they would have a lingua franca for exchanging rich information. Different kinds of data could be mixed together, allowing users to easily organize their data in a way that makes sense to them.
I proposed five requirements for such an information management framework:
- Be a useful and usable framework. This should go without saying, but it’s important to keep in mind that this framework can only help solve our information management problems if it is useful, and it is attractive for developers to build upon
- Extensible for new kinds of data. If the system is not built to be extensible, we will soon find ourselves right where we are now: doing today’s job with yesterday’s tools.
- Comprehensive search capability. This one should speak for itself. With the overwhelming amounts of information that we have to deal with, advanced search capability is an indispensable feature.
- All data on equal footing. Several of the problems I identified stem from the fact that in current systems, certain types of data are not first-class.
- Flexible organizational features. You should be able to organize your data in whatever way works best for you.
I believe that these requirements provide a good starting point for an information framework that application developers could build upon, and ultimately give us an easier, more usable set of information management tools.
And then I would have no more excuses for being disorganized.
Thanks for the good discussion of the issue. I think at least some of the issues you’ve mentioned have begun to be solved by next generations OSes. OSX, and Windows vista support, things like tagging and virtual folders which are akin to what you’ve mentioned. They’ve also allowed search to be more powerful so it doesn’t just deal with files. Search can return browsing history, emails, contacts etc…
Here’s an interesting demo of Vista’s search and tagging facility: http://www.istartedsomething.com/uploads/search.mov
There’s a good bit more work to be done before it comes to the level you’re talking about, but some of the ideas have begun to be incorporated ta least.
You’re right, the desktop OSes are finally giving us some better ways to manage our information. The problem is, it’s too late. For a lot of people (myself included), our personal information isn’t sitting on one computer. We’re using web-based email, Flickr, Del.icio.us, etc.
I deliberately didn’t go into that much technical detail in the article, but I think the real solution is going to need to deal with data that is distributed across many machines and web services. It’s really almost just an extension of semantic web ideas.
Thank you for an interesting article. I agree that organization of data is far from optimal. I think integrating web with desktop would be quite useful but very challenging at the same time. Having desktop be linked with web resources might raise some security issues. Combining several applications into one can create some bulky products with some features that not every user wants.
But I definitely, agree that there is a place for improvement. I use IPhoto to organize pictures on my computer and use Flickr uploader to upload the pictures. Finding an album in the IPhoto folder can be tricky because the names of the folders are different from albums’ names; the folders are numbered. Kodak offers a desktop application that has an easy synchronization with the online Kodak albums. As Patrick mentioned there are still problems with compatibility; I can use Kodak to synchronize with my Kodak album but not with Flickr. It would be nice if there were more standards and online applications could talk to desktop application independently from the brand. I can also see Web Services as an option to achieve this goal. I am not sure that the companies are interested in such friendly compatibilities though, i.e. Kodak might loose customers of Kodak online galleries because now these customers can easily work with Flickr.
Very good article. I have been having trouble keeping it all straight. I need a person mashup server. Anyone got any good ones? Tried PageFlakes.com, but then too, it can’t view anything on my person computers.
One of my co-workers did suggest Google Desktop. It took it about an hour to index one of my machines, but it has made a lot easier to find that one document that I created 5 years ago. Then I use targeted web searches to find my information on other sites (ex. Hex site:del.icio.us).
Finally, someone managed to sum up at least a good half of the usability problems with the desktop metaphor! And, without going into the somewhat abstract Sematic Information Modelling Paradigm Logic (SIMPLE), again.
I particularly liked the quote: “…is like a dialect private to an isolated town: as soon as we leave, we are forced to use the computer equivalent of grunts and hand signals.”
Great example! What isolated towns usually have is a language that is common with their neighbors, so they can trade photos, money and email! I did quite a bit of time on languages and communities in my masters so I’m very happy with this metaphor. My only worry is that some languages will die out if there is too much ‘extensibility’ (like OpenDoc) if there isn’t any support in the surrounding ‘villages’, the languages will disappear, perhaps even faster than languages die in the real world.
So, what’s the practical option? Want to make one??? Should we?? A village-to-village platform? VTV? I’d be happy as a dog in a field running from village to village to be a part of it.
A good place to look for starters, and perhaps what not to do, would be Haystack, via MIT:
http://haystack.lcs.mit.edu/
Now, they’ve been barking up this tree for a while, but something about it doesn’t quite sit right with me. I don’t think they are heading in the right direction. If you want to chat about it, email me, I’ve got tons of ideas on the back burner waiting to become soup de jour!
CD.
I wonder if microformats will offer any solution to what you’re describing. It’s more web-based and still emerging, but does have some potential.
I just found a decent presentation on them today: http://www.xfront.com/microformats/Microformat-Demonstration.html
What you are proposing exists at a the application level as
What you are proposing exists at the application level as General Knowledge Base including multiple classification, search across object types, etc. I enjoyed your article and will follow this thread more closely.
Kevin, I think you’re right — I do see Microformats as being part of the solution. As I mentioned in my earlier comment, there are several semantic web technologies that could be helpful in this area.
In reference to a Burton Group report on the subject, I blogged about the importance and utility of hypertext as the core for interactive and compound “documents” where, in essence, the idea of a document dissolves, replaced with a set of mechanisms for joining pages and data in the manner that is required given a certain context.
In the context of project requirements, you could have hundreds of separate pages that you need to allocate and re-allocate across milestones, then produce “document” views which slice the requirements by milestone or even by status.
read the full entry here
By the way: 1 month ago, my inbox dropped to 2 messages. A business trip caused me to let it slip into the 20s but I will get back down to 1 or 2 by end of week. My tools:
1) Traction for all the text content that I need to remember, share or track/manage
2) ACT to record contact actions and next actions.
3) A spreadsheet for a few simple needs like managing my trade show calendar and tracking sales
Nice article, Patrick. A very good conversation starter on a ubiquitous problem.
Having just seen the BumpTop demo I can’t help but think that there’s another dimension at play in achieving peak productivity, in finally getting “organizized”. And that is to take al the rich information associated with single objects and begin to apply them to groups of objects, either permanently or as temporary instances.
If I envision the BumpTop dektop metaphor as a portable workspace (which I do, because I am a dreamy sort), then I can use their “pile” interaction to create homogeneous collections of objects and begin to apply enriched labelling and metadata to this temporary collection. Because BumpTop is a platform already (albeit for tablet PCs only), the only remaining hurdle is to extend the object model to include all the whiz-bang features of Flickr, del-icio.us, Gmail, etc.
Who knows when, or if, this will happen, but after years of wandering in the same dark forest you portray I can at least say I have a vision of one possible solution.
Look forward to reading more about everyone else’s.
BumpTop is definitely cool. I would say that it is approaching things from the opposite direction though. I am interested in creating in the semantics of the objects, in defining a sort of vocabulary in which you can describe and interact with them. If this were in place, then BumpTop (or any other interface) could be used to manipulate and organize the objects.
Some branches of inquiry that your article inspired when I read it – that’s a compliment, by the way 😉
1) When discussing information accessibility and portability, one invariably strays into “universal object format” territory, and some interesting thought has been done on that subject. We have different formats – because we have different applications – because we have different users – who have different ways of thinking about the data they care about. Is there a useful meta-meta data format that will allow ANY information to be uniformly described, stored and delivered in a way that is useful to ANYONE? To realize your vision, you need that.
2) Personal data are weird – they don’t organize exactly like objects and tasks in the physical world. With data, we use applications and tools in part to achieve useful groupings (“Recent documents” lists are a good example) but we don’t find the hole we were digging last week by grabbing the shovel we used to dig it. It is somewhat intuitive to group information by what we do with it and the tools we use to manipulate it…
3) Are tags and labels universally useful? Maybe, but there are other ways to approach organization. In a perfect implementation of what I call the “Google Mail Vision”, you would have only 2 classifications for your data – “visible” and “not visible”. When you want to see data that is in the “not visible” state, you search for it to make it “visible” (in a search results list). What if the data itself does not contain search-able bits that are intuitively useful for searching on directly (e.g. compressed media, or music and picture files)? Currently, you bandage on a fix in the form of a tag or grouping that will immediately come to mind when you are looking for those data. But one day, your search tool might be smart enough to fingerprint and relate your data across many dimensions (e.g. English language and audio, emotion and imagery, etc.) and show you useful results without you having to pre-organize it. I see the benefit in combining that with tags, but there is a point of diminishing returns. You end up searching for tags and within tags anyway…
4) In my opinion, this brings into focus a somewhat perpetual issue in the development of humanity – we have and always will advance our ability to collect more and more information. We then develop methods for storing and processing that information, and as a species, one of our primary methods is specialization within societies. But the kicker is that until an individual can physically exist forever, he or she will always be forced to decide what to store and process PERSONALLY. Thus, we must each devise a unique methodology that implements certain tools and information taxonomies, spending time to organize either in front of the process (i.e. creating folders and tags for browsing) or on the back end (i.e. searching). In my HUMBLE opinion, this means the affliction of disorganization is most effectively treated by pruning the set of data you are trying to organize. That strategy even works great for life away from your computer!
Thank you for the article…
Patrick,
Thanks for raising this. I was taken by your point about how different applications are mini-environments that we have to negotiate between. What a waste.
If you haven’t already, have a look at Jef Raskin’s The Humane Interface. (Summary here: http://jef.raskincenter.org/humane_interface/summary_of_thi.html.) He argues for abolishing: file names, folders, the distinction between files and applications, and anything that makes you switch modes (your uploading photos example comes to mind). He’s for: ways to use humans’ innate spatial wayfindng abilities and focusing attention on the task at hand. His zoomng video space metaphor is really fascinating.
p.s. His ideas are being actively pursued (http://rchi.raskincenter.org/index.php?title=Home) though I’ve only just discovered this.
I agree that there should be one way to access all types of data, and also that it should not just be about the platform but can work across various platforms. Someone else mentions the Raskin work, it’s definitely worth looking at – sounds like people are doing what should be done – responding to the need by pushing through the current limitations and barriers and taking it to the next level. Very interesting, and long overdue concepts!
Great ideas! My only complaint is that you started with “Requirement 0” in your first list, and then 1 in your second list. First thing it’s inconsistent and secondly why start with 0 anyway? That is one of my pet peeves. 🙂
I have been looking for some sort of tool to help me sort out my own data but also for use in assisting my clients undertake content audit and migration. After trialling a few options i’ve now been tinkering around with what so far looks to be a great little application that i found here at http://www.tag2find.com
It stores tags in a database and within the file also so that might help a few people with questions in this area. They are also very close to releasing the API for the application so for those of you looking for the storage of your index online for access across multiple PC’s this i’m sure something would surface pretty quicking.
Google Desktop apparantly has this web based index as an advanced option, however it was not quite my cup of tea as I need to control my vocuabulary of metadata tags.
The problem you found of not having an equivalent way of sending photos and music is really telling: iTunes work model is artificially crippled because it doesn’t want to let you easily share your music. Somehow, it is assumed that the pictures you have in iPhoto are of your own making, but music isn’t. At least, iTunes gives you a direct link to the file in your hard disk —something shared by iPhoto—, and it is also easy to send an e-mail with attachments just by dragging a file to Mail’s Dock icon.
So not only standard work models are needed (which sometimes are proven wrong when a simpler to use tool is developed), but also no artificial restrictions on what we can do with information residing in our computers.
There are digital organizers (with Ramanujan mechanomprphs in the high tails and savants in the low tails) and there are analog organizers who simply know that there is a document somewhere and will morph tools when needed (B-organizers).
Abe Maslow discriminates between these two in his “Theory Z” (www.maslow.org/sub/TheoryZ.php).
So climb onto the other side of the tube.
Divergent mind vs. Convergent mind?
And as Drucker pointed out in his “Management for the 21st Century”(?) book, there are readers and listeners.
Well, add divergent and convergent, and get a matrix. Are you leading your fish to a goal, or giving him more fuel
for his ideaphoria? I guess this would mean to hire writers and boiler room folks according to their Weltanschauungen.
It’s really nothing more than hierarchy and UNIX tuning.
this is a great article and i can’t believe so many of us don’t already do this. we are so caught up in today we haven’t learned from the past.