One of the most frequent tasks on many intranets is finding people within the company. Providing an effective way to search people is thus a key goal in designing intranets. This goal becomes even more important for an organization like Emirates, a leading international airline, which has over 35,000 employees with over 140 nationalities and where more people are likely to use this feature more frequently.
Our intranet provides many applications that have a people finder feature to help staff find each other. The goal in using this feature varies depending on the application and situation. For example, people may want to find a staff to book a meeting or add them to a project team. Whatever the goal, a simple text input field and a Find button are enough to provide the sought-after results. But again and again I have heard complaints about not being able to effectively find colleagues using this feature.
The effectiveness of the People Finder feature is challenged in the following ways:
- People misspell names of staff they are searching. (e.g., ‘Vivek’ is spelled as ‘Vevek’; with over 140 different nationalities this is bound to happen.)
- Names stored in the database are not in proper format. (e.g., ‘Vivek Deshmukh’ is stored as ‘Vivek D.’)
- People are known by completely different names than the one stored in the database. (e.g., In some cultures women change their names after marriage.)

Figure 1: A typical example of not finding a person in staff directory
How can you design a better People Finder application than the one that so often says “Staff not found!”?
Building on users efforts
One idea is to look at what users do with the problem at hand and how they solve it, and then use their efforts to build the application. For our People Finder application we can do this by having a “Did you mean …” feature, which gives alternative name suggestions to users. These suggestions are not built by pre-defined logic but are based on the collective input of users.
In our department, when colleagues don’t find someone on a People Finder application, they try various strategies. These include:
- trying different spellings,
- asking another colleague for the persons correct name and spelling,
- calling the person directly (if they have their phone number), and
- checking previous emails to get the exact spelling.
Whatever activity they choose, they make sure that they have the right information to type in the People Finder text box. We need to make use of this effort (i.e., making an error and then fixing it) from the users to build our application. The following conceptual model is my attempt at designing such a system.
Building the application
There are five essential components to this concept:
- Build a relation table to store incorrect entries. In other words, store search queries which produced no results.
- Determine if the user has found the right person.
- Build a relation between the previous incorrect entries with the last correct entry determined in step 2.
- Check the strength of relation by observing patterns across all users.
- Present strong patterns as a “Did you mean …” feature on the search results page.
Let’s look at each step in detail.
STEP 1: Build a relation table to store incorrect entries.
To explain the concept, let’s take the scenario in which a user Sally wants to organize a meeting with Timothy Campbell using People Finder but cannot find him because Timothy Campbell is stored as Tim C. in the application database. (See Figure 1 above.) Let us store this incorrect entry Timothy Campbell in a database table called “Relation Database Table for Sally” (See Figure 2).
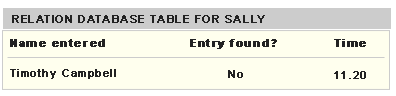
Figure 2: Incorrect entry inserted in the Relation table for Sally
STEP 2: Determine if the user has found the right person.
Next, let us say Sally tries a few more names in the People Finder text box, which generate no results. We store all of these incorrect entries in the Relation table. After a few failed attempts, Sally asks her colleague how to find Timothy Campbell in the address book. She is told his name appears in the address book as Tim C. Sally types the name ‘Tim C.’ and gets a result with Tim C.’s details. Sally adds Tim C. to the meeting list. It is this action of Sally clicking the Add button that allows us to identify a correct entry for the Relation table. (See Figure 3.)

Figure 3: Sally now types Tim Campbell’s name as it appears in the database.
STEP 3: Build a relation between the previous incorrect entries with the correct entry.
We then build a relation between the previous incorrect entries with the first following correct entry (i.e., Tim C.) and add it to another table called ‘Alias’ for the staff Tim C. Think of the Alias table as a ‘People also know Tim C. as …’ list. Note that the basis for saying that there exists a relation between the incorrect entries and the correct entry is the real life observation that people do what they must to find the correct name to type in the search text box. Of course you may get mismatches but this will be taken care of in the next steps.
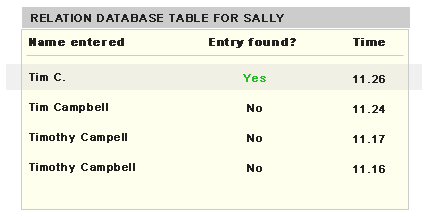
Figure 4: Tim C. is related with the previously typed names
Figure 5: Alias table for Tim C.
STEP 4: Check the strength of relation by observing patterns across all users.
Next we identify the most common aliases used for finding Tim C. We do this by looking at the Alias table for Tim C. Those aliases that appear frequently are strong candidates to be displayed with a “Did you mean …” feature. In our example Timothy Campbell and Tim Campbell show a good pattern across different users as aliases for Tim C., so we conclude that when people search for Tim Campbell they mean Tim C.
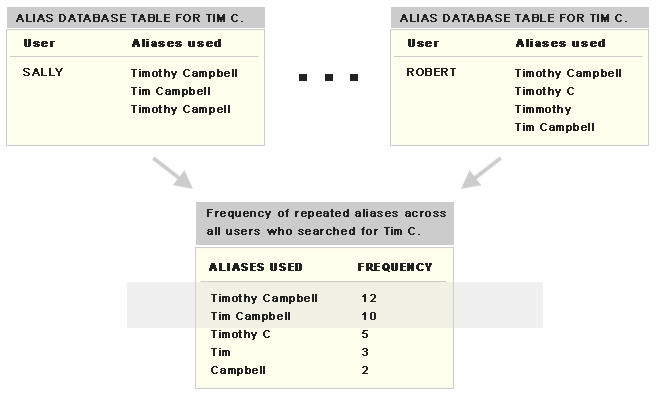
Figure 6: Alias table shows that lot of people type Timothy Campbell or Tim Campbell to find Tim C.
STEP 5: Present common patterns as “Did you mean …” feature on the search results page.
The last step is to present the most common pattern to the users as a “Did you mean …” feature. In our example when -users search Timothy Campbell we present them with Tim C. as a “Did you mean …” feature. We can show additional information like the department, title or a photo of Tim Campbell so that the user can confirm that it’s the person he is looking for.
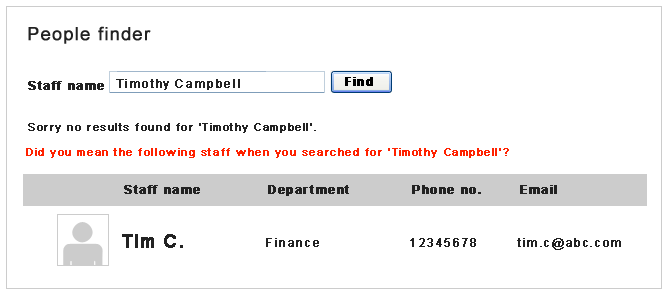
Figure 7: Implementation of the “Did you mean …” feature
Making the system efficient
The secret to making our system more efficient is eliminating -irrelevant relations. Consider this question: Should you build a relation between an incorrect entry which was entered at 08.30 and the next correct entry entered at 09.20? Probably not! It is very unlikely that the user will search for the same person after a gap of 50 minutes. A time frame of 20 minutes may be more realistic.
Advice on how to go about building such a system
- Build a business case
Building such a system will take time and resources. You will need to present an argument to management why this is important and perhaps make a business case for the effort. Don’t forget to include key stakeholders like Human Resources while presenting the business case. Here are some key points:- Users will save valuable time while searching other staff.
- Colleagues will not be disturbed – their time will be saved.
- Companies will save on phone bills and employee time.
- Systems become robust over time without additional work from users or a massive data cleaning effort.
- Collaborate and co-ordinate with different IT teams who build applications
Pepare a list of all applications that use the People Finder feature. Collaborate with the IT teams who are responsible to build these applications and work out a plan to implement the “Did you mean …” feature on the current applications. This task becomes easier if you have a centralized IT team. - Prioritize applications for implementation
Our system becomes robust when many users use the system. Start implementing the feature on the “Frequently used by many” type of applications first. These applications will give maximum value in shortest amount of time.
The risks
There is a risk that few users can work together to build a strong pattern of, say, “Jerk” with Rob Stevenson, thus manipulating the system. This can be kept in check by doing two things. If your company is like ours (formal and very particular about its image) you can:
- Keep pattern strength high especially if the suggestions to users are going to be automatic without human intervention.
- In addition to high pattern strength you can include a manual check done by HR admin who can authorize or investigate each strong pattern. To do this you will need to provide an admin interface to HR where they can monitor and dig deeper in to strong aliases.
Going forward
Just as users learn a new system by using it, possibly by making mistakes on the way, a system can also be ”trained" to learn from the users by continuously “listening” to users inputs, while helping users along the way. Though some development effort and technical know-how is required, more intelligent people-finding features on company intranets are essential. There is a long-term payoff, and companies will be saving a great deal in terms of employee time and costs.
“We can show additional information like the department, title or a photo of Tim Campbell so that the user can confirm that it’s the person he is looking for.”
The interesting thing is that, without this additional feature, a list of suggestions is close to useless, especially if you end up with more than one suggestion.
If I can recognize Tim by his phone number or email address, why not let me search by phone number or email address? You could even go so far as to have a few fields to describe Tim’s photo (“male”, “dark hair”, “glasses”, …).
Interesting, I hardly think of those technical solutions, but it does look like it should work.
Just an idea; When you are new in a company you might know a face, but don’t know the name. Something like “Guess Who?”, where you see a large group of pictures and can filter on variables that will immediately reduce the number of pictures shown, might help you find the name quickly.
(http://en.wikipedia.org/wiki/Guess_Who%3F)
(“random passerby” thought of the same thing)
Vivek, an interesting idea which might not only apply to a people finder, but also to contacts, e.g. in a CRM. The crucial point will be to build the relation between the unsucessful entries and the successful entry. How do you do it – manual by data stewards or using an automated process? Automating it would be the preferred way, but how do you prevent the system from creating wrong matches, e.g. when a person creates several queries in the given timeframe of 20 mins?
Do you update the matches over time and how do you deal with a larger number of people with the same name?
This is an interesting approach to the problem, but it seems a much simpler and possibly more effective approach would be to search across more fields (as first suggested here by Random Passerby). Users may remember other attributes about the person such as the department or division they are in, their boss’ name, etc. The addition of tags could also be helpful. For example, allowing employees to tag their own profile with relevant attributes such as their area of expertise, current and previous projects or teams they’ve worked on would increase their odds of being found and wouldn’t require a complex matching algorithm on the back-end.
I think the difficulty with this approach is that the quality is dependent in part on users in a certain state of frustration (possibly not their most collaborative moment). Also, it appears that this solution is most effective when input is collected from as many apps as possible – a costly operation at best. Another problem I see is when there are name clashes. The reason Tim Campbell was added as Tim C in the first place is probably because the company already employed a Tim Campbell elsewhere. Search from “Tim Campbell” in that case leads to a success in terms of “found” but it is a false hit. This complicates the overall design significantly.
How about considering participation from the one person who is best placed to be aware of the problem of findability: Tim C himself? Tim would probably know that people have trouble locating him. Let Tim populate the list of aliases so that others can use it to their advantage. False hits still are a problem, of course.
The idea of adding more details such as business area, phone number mail ID etc are all very valid – SAP does this all the time with their concept of matchcodes. Take a look at http://web.mit.edu/hr/compensation/quickcards/ASR-matchcode.pdf to see how MIT has implemented people search using SAP.
On Random Passerby’s comments,
What you are suggesting is to give additional flexibility for searching while my article is about how to make the best out of what the user has provided – i.e. show likely results even if what the user has entered is wrong. As you suggest, we should give him additional choices to search but what happens when the user makes an error while typing the email address? The article is finding ways to make use of these wrong entries so that later similar wrong entries will give desired results. I have given the example of searching by names but you can expand this by including email address or other variables.
Another thing, you are right that Tim’s Phone Number and Email Address will help users to RECOGNIZE him, but the question I would ask is will user’s REMEMBER the same information (Phone or Email) to be put in the input field?
On Julius Huijnk’s comments,
Interesting game Julius, thanks for the link. This is a wonderful idea to include as an advanced search feature. This will be especially useful for multicultural environments where people will have visually distinct characteristics.
On Alexander’s comments,
You are right on dot; the crucial point is in making those relations between incorrect and correct entries. In my example I am building those relations automatically based on user’s actions (Clicking add button). This action indicates a correct entry which is tied to the several incorrect entries. For your example you need to identify what Action the user takes after he gets the search results, does he click the name link? does he click a button? does he select the user from a list? etc. You can’t prevent the system from creating wrong matches but you can restrict displaying these matches by first checking if the matches show a good frequency across different users.
It will be a good idea to keep the matches fresh over time, though I feel it will be purely speculative to define a particular period. If you find a rationale to do that then please let me know 🙂
With large number of people with same names we can use the Alias table (fig. 7) to display the high frequency names at the top of the ‘Did you mean’ list while the lower frequency will automatically fall at the bottom. This means that highly sought after staff will be listed at the top of the results page. The additional information like the photo or department will help users identify the correct person.
Hi Vivek
Thanks for an interesting article.
Search is not an area of expertise so forgive me if this is a dumb comment. I think it’s great that you’ve recognised that matches may not be found because of typographical mistakes and the like. However, shouldn’t a good search algorithm look for and return close alternatives (i.e. use fuzzy logic) when searching for matches? By this I mean that if someone searches on Tim Campbell, then Tim C should come up as a match anyway – albeit one with not as much relevance as a full match – because the “Tim”s match and the “C” matches?
Your alias approach could then supplement the in-built flexibility to continually improve search results over time.
Regards,
Jessica Enders
Principal, Formulate Information Design
http://formulate.com.au
Vivek,
thank you for a well written and explained article. It has given me a load of ideas that may just help in a couple of places, especially in creating an assessment for my students 🙂
In reply to Jessica Ender’s comment:
One such “fuzzy logic” method to suggest alternatives to similarly names comes in the form of the SOUNDEX code. This enabled Smith Smithe Smyth Smythe all to be recognised as “the same”.
Add this to the people finder base algorithm and you automatically extend the possible results.
I agree that the concept works exceptionally well in theory and would provide a beautiful method to add to the search arsenal in a contact manager or similar. Take the “Tim C” approach one step further and add nicknames to the search pool and you possibly gain another ‘fast find’ factor to the method.
Adrian, Lecturer Swan TAFE, Midland Western Australia
@Vivek: Thanks for the inspiration! I’d love to give that system a try. But I guess it needs a reasonable number of searches, failures and refined searches in order to come up with reliable patterns. Unfortunately I don’t have a suitable system at hand to try it out.
@Adrian: Soundex might be good for the English names, but remember that the problem described deals with people from 140 countries. Soundex isn’t reliable for a corpus with that many different pronounciation schemes.
What really made me think was the example with people who married and changed their names. Off course, if the person had their maiden name in some alias field and if that field was index as well, we’d be fine. But the real world is far from perfect – and the bigger the companies, the more difficult it gets to maintain central databases like that.
For me, the idea to observe users and create a benefit from their behaviour is what is actually important here, not just technical ways of how to match strings (from user intput) against strings (in a database/index). Again, thanks for that inspiration!
Marian