“A controlled vocabulary is a way to insert an interpretive layer of semantics between the term entered by the user and the underlying database to better represent the original intention of the terms of the user.”The most effective communication occurs when all parties involved agree on the meaning of the terms being used. Consequently, finding the right words to communicate the message of your website can be one of the most difficult parts of developing it.
When we converse, we speak in “natural language.” This is language in all its raw, rich, gooey glory. When we organize our information and label it however, there is so much richness, variance, and confusion in terminology that we often need to impose some order to facilitate agreement between the concepts within the site and the vocabulary of the person using it.
This order can come through a controlled vocabulary. Amy Warner defines a controlled vocabulary (CV) as “organized lists of words and phrases, or notation systems, that are used to initially tag content, and then to find it through navigation or search.” This means that a CV is a type of metadata that functions as a “subset of natural language”(Wellisch); it is not how we normally speak. Using a CV is also a way to overtly display relationships among the various concepts that your site covers in order to increase findability. The most basic, and often overlooked, form of controlled vocabulary is a consistent labeling system. If you are careful to call the same thing, or the same concept, by the same name everywhere on your site, you are using a very simple controlled vocabulary. And you’re also ensuring that your users start developing a mental model of the information they can find.
A controlled vocabulary is a way to insert an interpretive layer of semantics between the term entered by the user and the underlying database to better represent the original intention of the terms of the user. Consider what happens when you do not use a controlled vocabulary. An uncontrolled vocabulary simply uses the natural language of the documents and matches that with the natural language of the user. This is extremely specific, and it gives the user exactly what they ask for. Sounds great right? Consider, however, a site about chemistry, where many of the documents use the chemical name of the element (“iron”), and many use the chemical symbol of the element (“Fe”). Using an uncontrolled vocabulary, the results will only include the terms entered by the user. If the user entered “Fe” in the search box, he will not get any of the results for documents that use the term “iron.” There is a good chance the user is missing some documents he would like to have. Very few users will enter both terms, and many will be reviewing their results thinking they are seeing the results from all relevant documents.
The equivalence relationship
You probably are aware of certain categories or items on your site that might go by multiple names. You realize that if you said “automobiles” on your homepage and “cars” on the next page, users might get confused. Users will start to wonder if there is a difference between the two terms. Instead you choose “automobiles” and don’t use “cars” at all. In this case “automobiles” is the term you prefer to use throughout your site. We call this the “preferred term.” “Cars” is a variant term, a different word representing the same concept. Or, consider this example:
![]()
Here, each term refers to the same concept, Elizabeth Taylor (your preferred term). We could tell our system, when people ask for “Elizabeth Burton” use “Elizabeth Taylor.” This is more traditionally expressed using standard CV notation as:
Elizabeth Fortensky USE Elizabeth Taylor
Elizabeth Taylor UF Elizabeth Fortensky (UF = Use For)
Or even this:
Liz Taylor USE Elizabeth Taylor
Elizabeth Taylor UF Liz Taylor
Think about Gap’s web page (http://www.gap.com). We already know what they sell (they have excellent branding), and most of their content is generally referred to by the same terms as used in our general culture. In other words, people consistently say “jeans,” “pants,” and “shirts.” Even though you might get the occasional person using the word “dungarees” or “slacks,” nearly everyone would see “jeans” and know what the category referred to (the visuals help support this too). Furthermore, Gap does not carry hundreds of pairs of jeans that must somehow be distinguished from one another. If you examine the natural language people use when talking about Gap’s products, there’s an unusually small amount of term variance. Content like this works great in the very simple organization system used on the Gap site. It works so well that they do not even need to offer search; this is very unusual for an ecommerce site. What they have is a system in which all of the concepts are consistently labeled using language familiar to their users. They’re lucky. Few sites have the option to work in this way.
Let’s say, however, that gap.com decided to offer search. Then they would somehow need to translate the natural language of search into the controlled language of the website. People search in the same language they speak, natural language, so a more advanced controlled vocabulary needs to take the concepts of your users (natural language) and match them to the concepts expressed in the language of your website (controlled vocabulary). That means if the developers of the site began to see that people were searching for “dungarees” and getting zero hits, they would need to create a way to tell the system, “when someone searches for ‘dungarees,’ give them the results for ‘jeans.’” In the language of a controlled vocabulary, “jeans” becomes the preferred term and “dungarees” is a variant term, and they have an equivalence relationship. This can be a powerful tool for increasing findability.
There are many examples of the situations that alternate terms cover. Here are a few:
- synonyms (two words with the same meaning, like “jeans” and “dungarees”)
- homonyms (words that sound the same, but have different meanings, like “bank” the financial institution and “bank” the side of a stream or river)
- common misspellings
- changes in content (e.g., countries that change their name or have multiple spellings)
- identifying “Best Bets” or the most popular pages associated with a certain term (http://www.BBC.com is great at this)
- connecting a woman’s married name to her maiden name
- connecting abbreviations to the full word (e.g., NY and New York, the chemical symbol Si with the element Silicon)
There are two types of synonym equivalence lists: synonym rings and authority files. Synonym rings are generally used for searching behind the scenes as a way to connect the various terms for a concept. It can be used to say, “when someone searches for “Si,” give them all documents with both “Si” and ‘Silicon.’” However, what happens when you want to display one of these terms in your navigation? Then you will need to pick one to be your preferred term. Now, you have an authority file. In each of the above examples, different terms may be used, but each one represents the same concept. They are tied together and given meaning by making their equivalent relationship explicit.
Hierarchical relationships: broader and narrower terms
If your content is more complex, for instance if you sold only pants and you had hundreds of types, you might require more from your controlled vocabulary.The natural language we use to describe the concept of “pants” quickly enlarges as “pants” becomes more specific. In other words, “slacks,” “khakis,” “jeans,” “trousers,” “corduroys,” and other kinds of pants will all need to be differentiated so users don’t have to rummage through pages and pages of search results for the word “pants,” when pants are your whole inventory.
![]()
What will help is a systematic way to map out the different terms so people quickly find the specific kinds of pants they are interested in. What you need is a hierarchy showing the broader terms (BTs), the narrower terms (NTs), and the variant terms (most often displayed as “USE” and “UF” for Used for). These will show which terms are subsets of larger, broader concepts. You are starting off with a jumble of words that are all related to “pants” in some way. It might look something like Figure 2.
We have a bucket we can call “Pants” and inside are a lot of terms with a relationship to the concept of pants. In this example, “pants” is the broader term, and the kinds of pants refer to subsets of the whole universe of pants. In a controlled vocabulary, we might reconfigure the chart above to look like this:
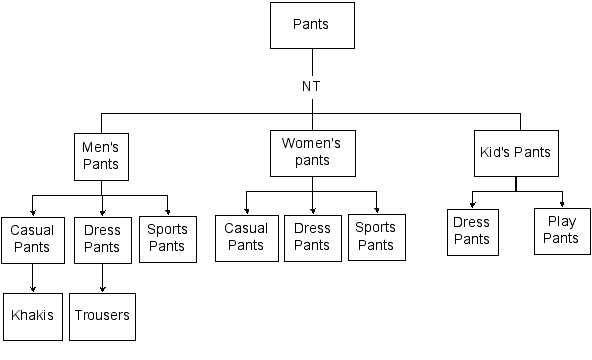
This is what people are increasingly calling a Taxonomy. This term makes traditional librarians a little uncomfortable, but we are learning to live with it. Originally it was a term for biological classifications (Genus, species, etc.), but has quickly become a standard word for describing hierarchies.
The standard CV notation used to express hierarchical relationships are NT (narrower term) and BT (broader term). Using this notation, the term “Women’s Pants” would be expressed like this:
Women’s Pants
BT Pants
NT Casual Pants
NT Dress Pants
NT Sports Pants
There is a lot you can do with this hierarchical arrangement. It can help you formulate your homepage navigation. It could improve your searching and browsing. It can help users broaden and narrow their search results quickly by showing them where each set of results fits into the site’s hierarchy (see Keith Instone’s “attribute breadcrumbs” for more examples). Generally, few sites need to go beyond the level of a taxonomy, but it might be useful to see the next level of complexity in controlled vocabularies.
Associative relationships: related terms
How far can I extend the pants example? Oh, quite far. Let’s say that you are a research institute that studies pants (ridiculous I know, but stay with me). You not only study pants themselves, but the materials they are made from, their history, how they are manufactured, and more. Your institute might do well to take the time to develop what Peter Morville has called the “Rolls Royce of controlled vocabularies”—a thesaurus. A thesaurus shows all of the relationships described so far (BT, NT[LD3], and UF), but will also include related terms (RT). This is an associative relationship. It shows how one term is associated with another.
If a user looked to your institute for research on jeans, you would be able to give them that term embedded in a rich series of relationships. An example of the range of relationships would be expressed like this using the standard format for thesauri:
Jeans
BT Pants
NT Levis
NT Wranglers
UF Dungarees
UF Waist Overalls
RT Denim
RT Overalls
Denim is related to Jeans, but not hierarchically. It is not a type of jeans, nor is one a subset of the other. Yet someone interested in one term might be interested in the other because they are related concepts. In the interface, you might identify “Denim” as a “see also” option for “Jeans.” If users looked for the term “Denim” in the thesaurus they might see something like this:
Denim
BT Fabrics
NT Ring Spun
NT Dark Indigo
NT Stonewash
RT Jeans
The Denim example alone could be filled with many additional terms, and it is easy to see how well this would accommodate user browsing (and “berrypicking”). This is also one of the dangers of creating associative relationships: knowing when to stop. This relationship is also the most difficult and subjective of all the relationships in a CV. You are identifying a relationship between two concepts that may not be obviously apparent. On an Amazon product page, when the page identifies an item that others have purchased along with the one being displayed, Amazon is identifying a potentially useful associative relationship.
To push the concept a little further, if a user is interested in a paper from your pants institute on the “Hemingway wore khakis” advertisement from Gap, they might also be interested in a paper you have on how it was really Rock Hudson’s subtle use of Khakis that made “A Farewell to Arms” such a great movie. The connection between the two documents, the intersection of the concepts of “Hemingway” and “khakis,” is less direct than the Denim example above. This is expanding the concept of “related terms” farther than many would be prepared to go, but it is an option.
Internal uses of controlled vocabularies
So far, we have focused on how controlled vocabularies help the user, but there are also benefits to the organization using the CV. Here are a few:
- CVs can help with category analysis or keeping your categories distinct.
- CVs can help establish a site’s navigation.
- CVs can be the basis for personalization features.
- CVs can help with preparation for CMS or knowledge management projects, since many of these require this sort of structure to your content to do their magic.
- CVs get the organization using the same language as the users (which should result in better communication with them).
- CVs can help the organization (and the user) understand what concepts your site covers. Your controlled vocabulary is in reality a “concept map” of what is on your site.
While controlled vocabularies can be powerful, by themselves they are not the magic pill that will cure what ails your site. CVs are a lot of work, they are often difficult and time consuming to maintain, and they can be very political. Some skepticism toward all metadata is a healthy thing (everyone still reading this should see Metacrap). As with anything important, there are a lot of people who are doing it loudly and badly.
Conclusion
Human beings are natural makers of patterns. That is how we understand what our senses are taking in. When people visit your site, they will immediately begin trying to understand what they see. A well-designed and regularly updated controlled vocabulary can help connect the concepts your users have in their heads to the concepts you present on your site. That is when real communication will occur.
Next in the series: How to create a controlled vocabulary.
- Wellisch, Hans. Indexing from A to Z. New York: H.W. Wilson, 1995. p.214
- Amy J. Warner Taxonomy Primer
- http://www.BBC.com
- Keith Instone’s attribute breadcrumbs
- ASIS Summit 2001
- Berrypicking
- Metacrap
- An Annotated Bibliography
Karl Fast is a PhD student in library and information science at the University of Western Ontario. He also has a master’s in LIS. His graduate work has included courses on organization of information, subject analysis, thesaurus construction, and facet analysis.
Fred Leise, president of ContextualAnalysis, LLC, is an information architecture consultant providing services in the areas of content analysis and organization, user experience design, taxonomy and thesaurus creation, and website and back-of-book indexing.
Mike Steckel is an Information Architect/Technical Librarian for International SEMATECH in Austin, TX.
The use of of the word “ontology” to describe the creation of knowledge domains actually pre-dated the W3C. It was actively used in the AI field in the 80s (and probably earlier) for people active in designing expert systems., which involves more than controlled vocabularies. In creating models, one is also creating theories about how the models will be designed (for example, describing how spatial and temporal concepts shall be represented). Many people active in ontology work for the past three decades have backgrounds in philosophy and mathematical logic. Some philosophers disdain “applied ontology” work, but it seems like a reasonable extension. The epistomological aspects are part of the knowledge elicitation processes within ontological engineering, so it’s all related. 🙂
This is a great article! I’m going to ask my students to read it. I’m an instruction librarian and many of my students have a tough time with the concept of “controlled vocabulary.”
Thanks!
Raffaello and SC, thanks for your kind comments. Glad you’ve found the articles useful.
This is really a wonderful idea unheard of, great, how did you think?windows7ultimatekey
omaha homes for sale Find the house of your dreams
It might be useful to point out that the term relationships you describe are specified in a formal standard: “Construction of Monolingual Thesauri” — ANSI Standard Z39.19.
There are relatively inexpensive software applications to support construction and management of thesauri. Most, if not all, support the ANSI standard. See http://www.asindexing.org/site/thessoft.shtml.
For those interested in “faceted classification,” Peter Van Dijck and I have just started a Yahoo mailing list at http://groups.yahoo.com/group/facetedclassification.
Phil
Just so people know, we’ll be getting to standards later in the series (I think). And we’ll definitely be covering facets (which was the impetus for these articles).
For now though, we’re covering first principles.
–karl
Great article! Another reason to use CV’s in the company is ease of translation. If you are translating a manual in 40 languages, the amount of money to be saved and increased accuracy sometimes even makes it worthwhile to have not just a CV but a controlled language, including limitations on use of grammar. See http://poorbuthappy.com/ease/000563.html#000563
While we are on the subject of vocabulary, I’m going to share my experience of reading this article…
In Britain, and maybe other English speaking countries, the ‘self-explanatory’ example of Gap’s labelling is actually bewildering. Pants are underwear in the UK. The US sub-set ‘trousers’ is the UK super-set for all the jeans, dungarees, slacks, etc mentioned here. That’s for about 57 million people, probably more.
I was gently amused by the images the article conjured, but then realised my point was not as trivial as I first thought. Once the science of pattern-making is explained, the next step is the art of choosing the appropriate content. ‘Pants’ is not a culturally sensitive choice of example… but it does raise the question of how one deals best with clusters of users holding not only variant, but contradictory, semantic hierarchies.
I look forward to acknowledgement of cultural aspects in the promised future column on building CVs.
Excellent point, Ann! I even lived in England for a year and had an embarrasing incident involving a misunderstanding of the meaning of “pants” (which I will not replay here) and it still didn’t register with me when doing the article. It is very difficult to overcome our cultural understandings and your point is far from trivial. Sites should probably assume their audience is a global one. It also raises a good point about user testing. Often, we test people from within our own culture and don’t realize we have used an example with a different meaning elsewhere until someone from another part of the world points it out to us. Thanks.
One advantage of a controlled vocabulary is that you could easly switch terms such as trousers and pants, depending on whether the user perfers British or American English. I suppose one would require metadata to implement that kind of conversion, but you certainly can’t do it without a CV.
Even without hierarchy, having a set of standard terms also makes information more accessible to people who don’t speak the language well, or are simply unfamiliar with the jargon. When I don’t know what’s going on, seeing consistent labels makes me more confident in my understanding and I trust the presentation much more.
Controlled vocabularies are being used on web sites and in search engines to aid site search, and are also closely related to so-called “knowledge ontologies”, which are integral to the W3C’s Semantic Web initiative. See:
http://www.ksl.stanford.edu/people/dlm/papers/ontologies-come-of-age-mit-press-(with-citation).htm
http://www.w3.org/TR/webont-req/
Work on knowledge ontologies is also at an advanced stage in medical informatics. See (eg):
http://www.SNOMED.org
http://www.nlm.nih.gov/research/umls/
This shouldn’t be taken as a vote *against* CVs, but this article made me think that sometimes it can be overkill:
http://www.informationweek.com/story/IWK20030122S0010
– City Ogles Google Impact [San Diego Switches to a Google Appliance]
…which shows that very good search technology can still eke out good results from large amounts of poorly tagged content.
Search is not the only thing CVs are good for, of course.
The example may confuse those not accustomed to thinking carefully about hierarchies. Several kinds of pants, e.g., “Casual pants” are shown as Narrower Terms under Men’s pants, Women’s pants, and Children’s pants. This treatment is both illogical and not helpful to users. For example, if your user has navigated to “Men’s pants,” you don’t want to tell him/her that “Casual pants” are a kind of men’s pants, when casuals will include women’s and children’s too. Perhaps the authors are assuming a vocabulary would include three different terms that looked identical but required the next broader term (e.g., “Men’s pants”) to specify their meaning. But if you’re operating this way you’ve gone beyond controlled vocabulary into classifications and notations.
Before being co-opted by people of the W3C, et. al, the word ontology used to mean and still means to me the metaphysical study of the nature of being and existence. Ontology is related to metaphysics, which is the study of being and knowing, as well as epistemology, which is the philosophical theory of knowledge.
What the W3C and others mean when they use (rightfully described as incorrectly use) the word is the phrase ‘knowledge domain’. A knowledge domain is a controlled vocabulary and associated phrasings, i.e., representation language, used to express the content of a particular domain or field of knowledge. When the W3C and others discuss ontology, they not discussing ontology at all. Actually, they’re moving closer to the concept of epistemology.
This confusion should be nipped in the bud. It’s akin to the mistaken use of the word terror, as in ‘terror attacks’ when people, whether in government or in media, mean ‘terrorist attacks’.
This business about taxonomies today being different from Linaean taxonomies is something I’ve read several times today in different places. It must be in somebodies book that way, but it isn’t correct.
The terminology I ran across on an EDS ecommerce site is taxon and infon. Taxons are decisions. They result in branches. And, infons, the leaves of the decision tree, are the things being sorted out into the categories established by the taxons.
In Linean taxonomy, you have to ask the question “Hair?” to get to mamals. In your example, I have to ask “Man, woman, or child?” to get to Mens Pants. So there is no difference in terms of what is going on.
Hierarchy is a matter of a parent and child like car and engine. Hierarchies only get wide when there are decisions embedded in them. Even where I have a taxonomy like Truck, Ford Truck, Chevy Truck, I am asking Ford or Chevy. The only time you don’t ask a question is if there is only one child.
In electronics wires can lead from one point to many. That is represented by the same kind of lines you drew between your entities in your taxonomy. Where they intersect constitutes a “wired OR.” This means that there is a decision constituted by some logic.
We ask customers to naviage our taxonomies. They do this by asking questions. In e-commerce, shopping is naviagation. Shopping is asking questions like where is the men’s department?, where are the pants? Does anything fit? Those same questions need to be in the taxonomy if we our customers are going to have an experience congruent with their prior experience.
In response to David and his comments about taxonomies, the word taxonomies is a problematic one in this field. Taxonomy has become sexy and somewhat generic. This has created much confusion (even I get confused). Personally, I’d like to fit the word with some concrete galoshes and toss it over a bridge.
Taxonomy has been adopted by businesses to mean, roughly, a classification scheme. Now the purpose of a taxonomy is to classify and organize, and so this somewhat synonymous use of the word is understandable.
However, classification in library and information science is a vast and rich subject that extends well beyond how a taxonomy, even a Linaean taxonomy, classifies things. The famous Dewey Decimal system is basically a hierarchical classification system, but it’s not a taxonomy.
In our articles we are talking about “controlled vocabularies.” A taxonomy is a type of CV, consisting of preferred terms, all of which are connected in a hierarchy or a polyhierarchy. Terms in a taxonomy may also exhibit associative relationships, but it doesn’t have to. If it does have associative relationships we usually call it a thesaurus.
To put it a bit differently, controlled vocabularies is the generic type of “classification” system (I use that word loosely here). Synonym rings, authority files, taxonomies, and thesauri are all types of controlled vocabularies. What separates them is the types of term relationships they support. The simplest is a synonym ring. The most sophisticated is a thesaurus. A taxonomy is at the high end.
We are working on a glossary of terms for this field, organized as a hypertext controlled vocabulary. It should be published soon and should help clear a lot of this up. I hope!
–karl
I have just discovered your series of articles. Excellent writing! By the way: GAP has now implemented a search on its website. Unfortunately they are not using a controlled vocabulary… Search for “dungarees” and you will get the “We’re sorry, there were no results found for “dungarees” in all departments.”-message.
Kind regards, Felix