What is ontology?
An ontology is a formal system for modeling concepts and their relationships. Unlike relational database systems, which are essentially interconnected tables, ontologies put a premium on the relationships between concepts by storing the information in a graph database, or triplestore.
(The following examples use data derived from PLOS, which makes all of its Open Access data and content available.)
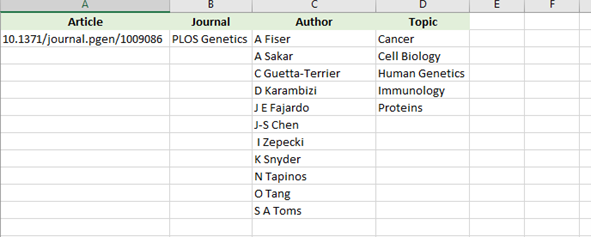
Relational databases are good at representing tabular data for one-to-one relationships:

However, real-life data is seldom this tidy; many-to-one and one-to-many relationships abound, which require additional tables and key-value pairs to represent data. Moreover, the relationships between the data elements is implied by the column headers but nowhere made explicit; you have to infer that “article number 1009086” “has the topic” “Cancer”.
So while the information below would require several (at least two) tables to represent:
…the same information is easily represented in a graph:
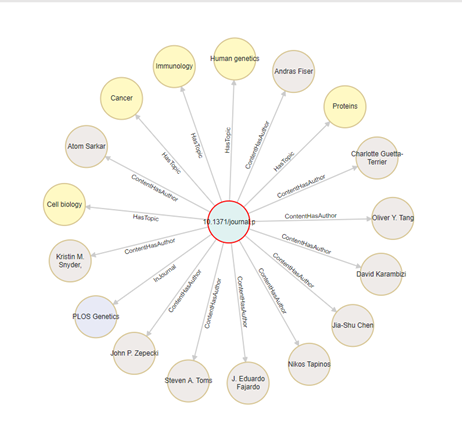
Crucially, the relationships between the objects (data elements) in the graph are, explicitly, objects in the system; they are represented by the lines, or edges, between the round nodes.
Further, we can expand any node on the graph to see additional connections.
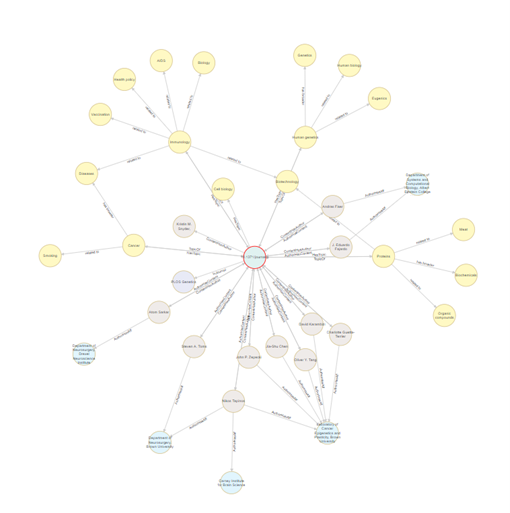
Lastly, note that the edges (relationships) in the graph are labeled and (potentially) directional. The relationships in the graph aren’t implied through columns with headers, but rather represented directly as objects in the graph (and in the system!).
That is to say: in an ontology, both the Boxes and the Arrows are of equal importance. We might also say that objects and relationships are both first-class data citizens.
Additionally, ontologies are:
- Extensible and customizable: existing ontologies may be reused and customized
- Shareable: ontologies are designed for re-use
- Interoperable: ontologies can be shared between systems (because they are standards-based)
- Machine-readable: ontologies are expressed using URIs (or Uniform Resource Identifiers) for identifiers which can be resolved using any compatible system
- Amenable to inferencing: ontologies allow reasoning over the graph to discover new, implied relationships and make them explicit; this can be used for machine learning-type applications
Ontologies are stored in RDF (short for Resource Description Framework), a Worldwide Web Consortium (or W3C) standard designed for this purpose. RDF is based on the concept of triples, which store information in a simple three-part format describing the two objects to be related (the Subject and Object) and the relationship (Predicate) linking them.

In this way, simple factual information can be modeled in a way that resembles how we understand facts.
A graph is essentially the sum total of all of the triples in the system showing all of the concepts and relationships.
Is an ontology just a fancy taxonomy?
Yes and no. All taxonomies can be expressed as ontologies, but ontologies admit more relationships between concepts than standard taxonomic hierarchical and associative relationships. This is outlined in the simple table below:

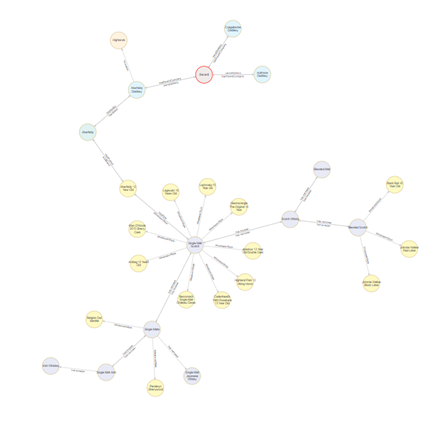
An ontology may include one or more taxonomies. A useful (but incomplete) way to begin thinking about ontologies is to imagine several taxonomies linked together. This example (an upper ontology) from scholarly publishing illustrates the classes of objects and their relationships in a model of the data in that ecosystem:
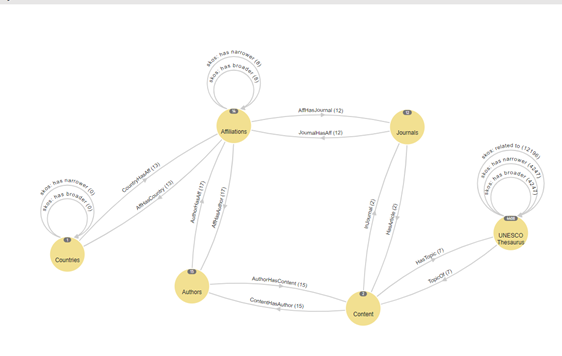
Circular lines represent relationships of a class with itself, so the UNESCO Thesaurus (a topical taxonomy) is permitted to have Broader-Narrower concepts, while the list of Journals is flat. Note that this scheme does not have any concepts; it is the upper ontology only: the model of abstract relationships between classes of objects.
To complicate matters further, SKOS is an RDF-compliant ontology data model designed to structure and share taxonomies. Ontologies essentially comprise two parts: the upper ontology, which is the schema used to define objects, their attributes, and relationships in a general way; and the lower (or domain) ontology, which is the data populating the schema(s). As noted, lower ontologies may be one or more taxonomies, flat lists (for example, of people), or any other collection of objects, each with its own set of properties (fields) and permitted relationships.
Here is an example of an upper ontology I devised to model whisk(e)ys. Note that there is no information about individual whiskies, distilleries, and so on; the model merely shows the classes of objects and the permitted relationships between them:
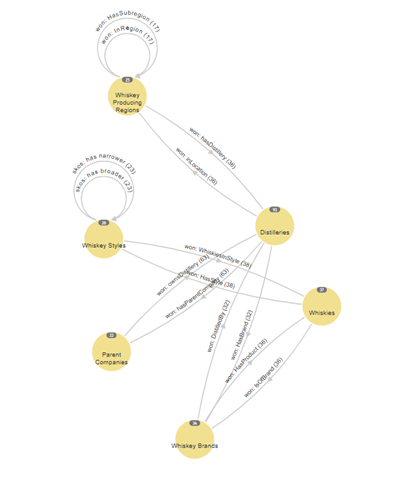
SKOS is therefore an upper ontology (an empty taxonomy schema) used to describe and store elements of a taxonomy, the terms and relationships of which comprise a lower ontology. In essence, the upper ontology is the schema describing the permitted objects, attributes, and relationships, while the lower ontology comprises the objects, attributes, and relationships themselves.
Many upper and lower ontologies are published as open data and can be adopted and re-used (given the appropriate permissions, if applicable).
Why would I need an ontology?
Ontologies are useful for expressing data in which the relationships between objects are important. In relational database systems (which are, to be clear, exceedingly useful for many applications) relationships between data in fields are implied by, for example, column headers, as shown above. In an ontology, those relationships are made explicit and exist as objects in the system.
This makes certain types of queries less expensive (in terms of processing time and power) and allows the traversal of information. Ontologies, as mentioned, also allow for inferencing: the addition of new triples implied by, but not explicitly depicted in, the graph. The stock example is still a good one. If I have triples stating

…as a person I can infer that John lives in England. I can also query this information and, if I like, add the triple “John lives in England” to my graph.
Graph querying is done using a language called SPARQL (for which you can find learning resources) that allows you to ask questions about and add information to your graph.
Ontologies are great for modeling,and storing information about, complex information ecosystems, workflows, products, customer information, and anything else that requires an emphasis on the relationships between objects.
How do I get started modeling an ontology?
As with any data modeling, begin with the objects you want to model and their attributes. Brainstorming the types (or classes) of concepts (nodes, boxes) and their relationships (edges, arrows) is a good way to begin.
For example, you may be representing People (customers, users, employees) which will require fields like name(s), email, location information, birthdate, or whatever other information is relevant to your systems and project. Another class of object might be Organizations (companies, clients, competitors, educational institutions, or whatever is relevant) which will require different fields (that is: a different set of fields) than People, which is what distinguishes them as a type of object. Commonly (although certainly not universally) some kind of conceptual or topical vocabulary—probably a taxonomy or thesaurus—may be used to classify content, expertise, products, or anything else. This will require another set of attributes with data to describe the concepts like definitions, links to Wikipedia or some other source with additional information, and Linked Data URIs to places like DBpedia or Wikidata—essentially, hooks to other ontologies to assert equivalence.
After drafting out the classes and their attributes, you can define the relationships (edges, lines) between the nodes. This can be basically anything you can imagine. Be precise; ontological relationships can be as richly descriptive as you like, so feel free to model exactly the useful relationships between objects in your information ecosystem.
Remember, though: you don’t need to get everything in on the first try. Ontologies are extensible, so it’s sensible to try to model and solve for some specific problem as you can always extend the ontology to include more later on.
It’s also crucial to remember that many upper ontologies (bundles of attributes and relationships, and often classes) are open and free to reuse. There’s no sense in inventing a field called “Title” for your content when Dublin Core already has such a field; it’s also easier to link your ontology to other ontologies if you reuse common and existing attributes and relationships.
Essentially, to create your ontology you can mix-and-match existing attributes and relationships gathered from other ontologies and combine them with your own attributes and relationships to create the data model you need. Since ontologies are interoperable (essentially: everything is a URI, following Linked Data principles) you can extend and customize your ontology schema as your needs grow.
We hope this serves as a good introduction without getting bogged down in the overly technical. We are always happy to talk ontologies; please reach out to bob.kasenchak@synaptica.com or ahren.lehnert@synaptica.com if you like.
Bob Kasenchak and Ahren Lehnert work for Synaptica, a leading vendor of taxonomy and ontology solutions.
Featured image: “The Flavour Thesaurus” by duncan is licensed under CC BY-NC 2.0
This is a great article and I’d like to share with my team, but the example images are too small/pixely to read. (I’ve tried on both desktop and mobile browsers.)
Hi Curt — thanks, and yes, we see that. We debated on how small things could be and it looks like we misjudged.
I’d be happy to provide you with a copy you can read; please drop me a line at bob.kasenchak@synaptica.com and I’ll see what I can do.
Bob
Great summary, I very agree!
Just one little aspect I often stumble upon when people talk about taxonomies (and thesauri) … that is to name the relationship a “broader term – narrower term” relation … but isn’t it rather a “broader concept – narrower concept” relation? Whereas the term – say – only linguistically represents the concept in a given language. SKOS does it right, IMHO, but in many taxonomy / thesaurus editors I continue to see the string “narrower term” … which feels a bit strange, I’d say.
Best – Michael
Yes, the difference between Term and Concept is more or less elided in much taxonomy practice (as you say), and in ontologies there is a clear distinction (as you describe). Taxonomy standards and abbreviations still tend (except in SKOS) to use the BT/NT nomenclature, which still sneaks in to my writing as that’s how I was trained. Using them interchangeably (which, again: guilty) is not good practice [note to self].
Bob