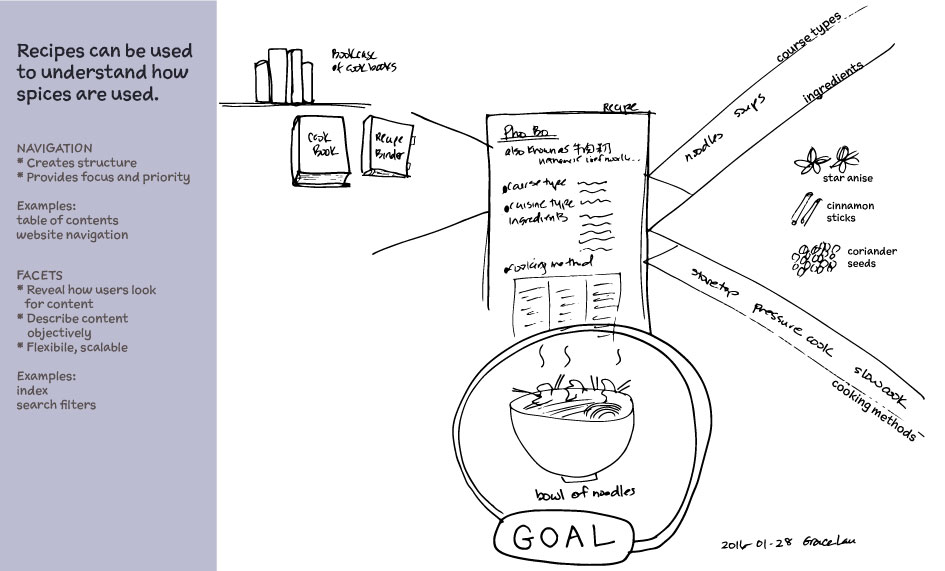
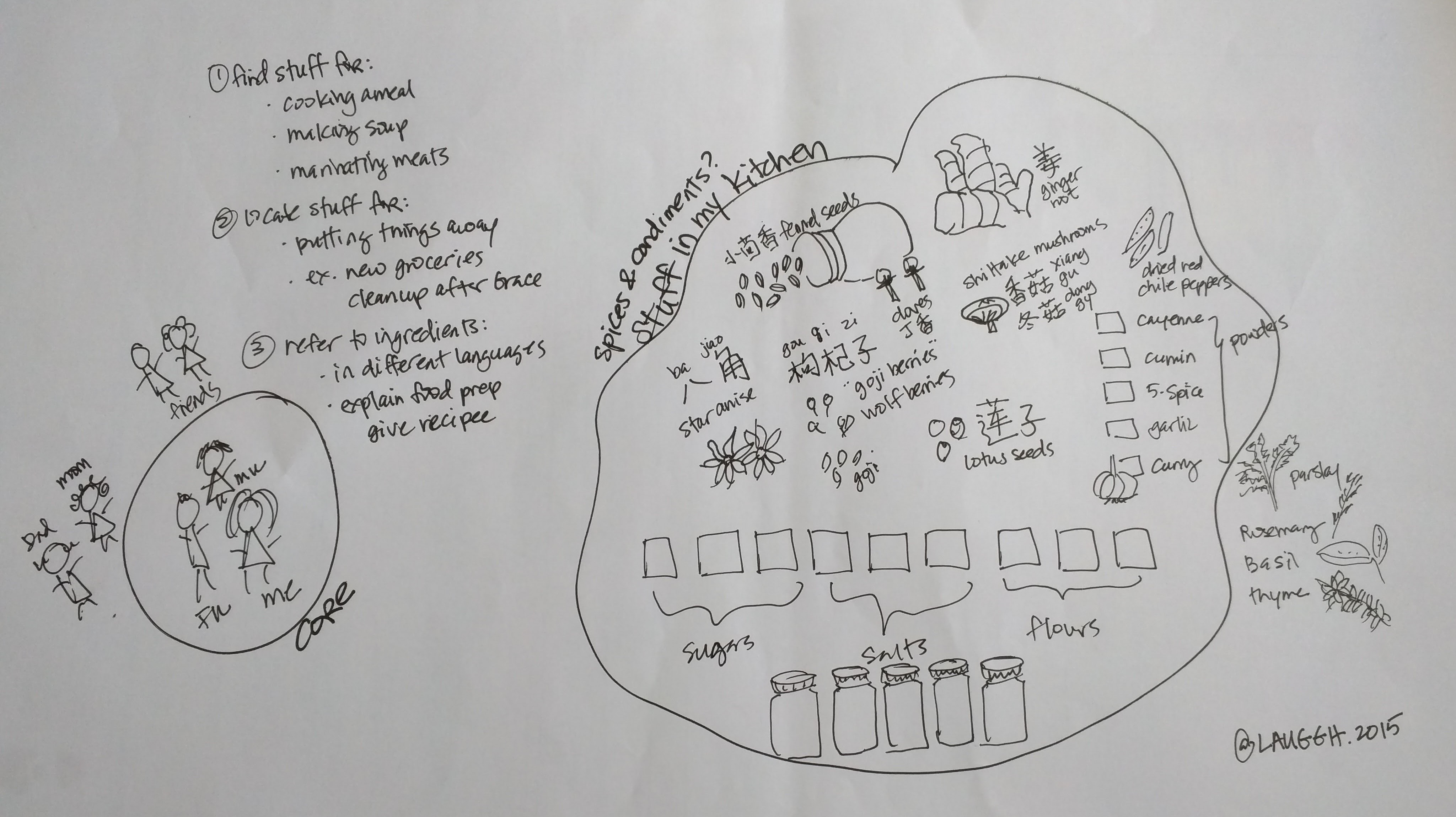
Validating with users is a fundamental part of the taxonomy recipe because all this planning and re-organizing is in vain if my in-laws come back in six months and the kitchen reverts to its original state.
Continue reading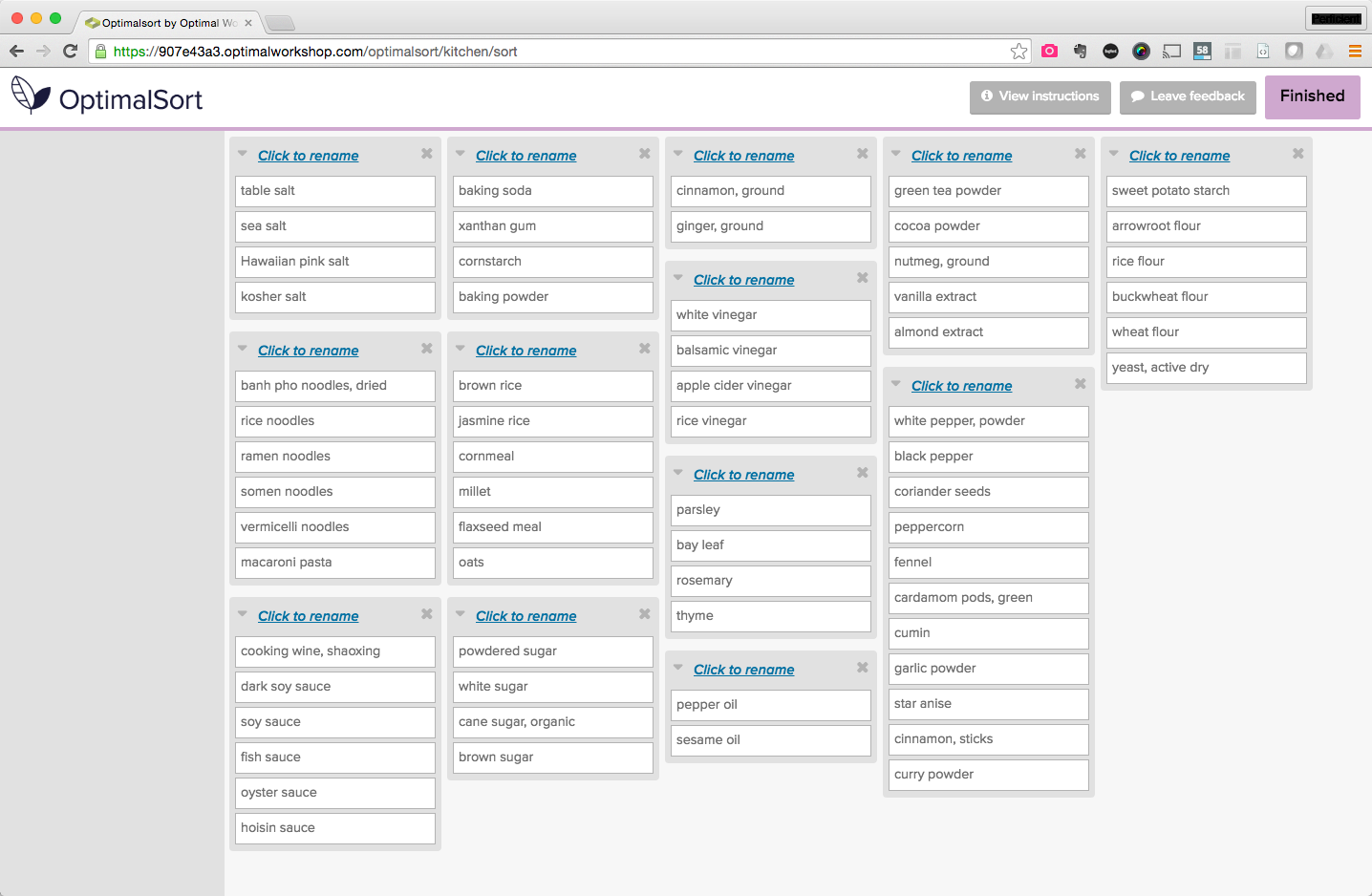
Card Sorting a Kitchen Taxonomy
Posted by